Meestal knal ik de blogs er in een paar uur uit, gaan die door naar de editor, volgt er een stukje spellingscontrole waar Word nog heel wat van kan leren, en dan verschijnt de blog online. Dit blog is anders, dit blog is al in revisie sinds februari, een blog over driewaardenlogica had allang online kunnen staan, maar ik wilde het over discriminatie hebben, en dat is een stukje lastiger. Tja, verschil moet er zijn.
Discriminatie betekent letterlijk onderscheid maken en daar is niets mis mee. Het splitsen van even en oneven getallen is bijvoorbeeld discriminatie, maar daar zal vrijwel niemand iets tegen hebben. Ik ga het echter hebben over een speciaal geval van discriminatie: racisme. Hoe je het wendt of keert, racisme is slecht, daar zijn we het wel over eens, toch? Helaas bestaat het wel en met de komst van kunstmatige intelligentie is het risico van onbedoeld racistische software een serieus gevaar. (Bedoeld racistische software is al sinds het begin van software een gevaar, laten we de KKK niet leren programmeren.)
Maar met zelflerende algoritmes gaat het onbedoeld ook fout en daar wordt dan ook voor gewaarschuwd door bijvoorbeeld de New York Times, of recenter de NOS. Ja, dat laatste bericht is uit mei. Dat is het nadeel als je lang over je blog doet, dan word je ingehaald door de NOS. Er worden in beide artikelen redenen gegeven voor waarom de algoritmes racistisch zijn geworden, maar het probleem ligt volgens mij dieper. Het ultieme doel van kunstmatige intelligentie is het nabootsen van menselijke intelligentie. Er zijn (helaas schrikbarend veel) racistische mensen, dus als je dat nabootst krijg je racistische machines. De vraag is dus, waarom zijn mensen racistisch?
Er zijn twee richtingen in de psychologie die het proberen te verklaren (er zijn er nog wel meer, maar ik zit al aan de 300 woorden, en ik ben er nog lang niet…) groepsgedrag en prototypering. Laten we beginnen met groepsgedrag, het idee is dat er een dierlijk instinct is dat je in een groep veiliger bent voor roofdieren (niet dat we ons in het dagelijks leven nog echt zorgen hoeven te maken over roofdieren, maar die instincten zitten heel diep). Het idee is dat je een groep maakt met iedereen die zoveel mogelijk op je lijkt en dan is het vervolgens met zijn allen tegen de rest. Over dit fenomeen is een aantal bekende films gemaakt zoals The Wave en Das Experiment. Mocht je die nog niet hebben gezien, ik vind ze aanraders. De film is gebaseerd op het Stanford prison experiment. Op dat onderzoek is veel kritiek, we moeten dus een beetje oppassen om het als pure waarheid aan te nemen, maar het is niet het enige onderzoek. In het experiment wordt veel gesproken over groepsdruk. Dat mensen onder druk heel ver kunnen gaan wordt ook bewezen door Milgram die in zijn onderzoeken schokkende resultaten laat zien. Nou is er ook veel kritiek over die experimenten, maar die gaan hoofdzakelijk over de ethiek er van.
Een ander bekend onderzoek toegespitst op discriminatie is dat van Jane Elliott waarin ze basisschool kinderen onderverdeelt op basis van hun oogkleur. Het laat zien dat de kinderen die op basis van hun oogkleur in de superieure groep zijn geplaatst zich ook superieur gaan gedragen. Als de rollen omgedraaid worden gebeurt hetzelfde, alhoewel wel in afgezwakte mate. Hoewel het de opzet van dit experiment was om discriminatie te laten zien en daardoor af te zwakken, geeft het goed weer hoe snel mensen opsplitsing in groepen accepteren en zich er naar gaan gedragen.
Hoewel dat een aardig verklaring lijkt, iedereen behoort tot zijn eigen groep en iedereen die buiten die groep valt wordt met een schuin oog aangekeken, blijft er toch nog wel iets knagen. Er is namelijk een probleem. In de hier genoemde onderzoeken worden mensen arbitrair in de groepen verdeeld. Het verklaart niet hoe er een overkoepelende groep is van mensen die je nog nooit eerder hebt gezien, terwijl onderzoek laat zien dat ook daar discriminatie duidelijk aanwezig is. Er is zelfs uit onderzoek gebleken dat kinderen een positievere blik hebben op witte dieren dan op zwarte dieren. Een verklaring daarvoor? Prototypering. Na een hele reeks zorgelijke menselijke eigenschappen tijd voor een klein stukje goed nieuws, want in prototypering zijn we als mensen dan weer heel goed. We gebruiken het bij iets anders waar we heel goed in zijn, object herkenning. Om dat uit te leggen wil ik je vragen om voor jezelf een banaan te omschrijven. Dan ga ik in de volgende alinea kijken of die van mij daar een beetje mee overeenkomt.
Geel en krom fruit. Was het een beetje in de richting? De banaan is een stuk fruit, dat staat buiten kijf (hoewel wat fruit is nog wel een discussie kan zijn), maar dat hij geel en krom is, dat is niet persé altijd waar. De banaan is krom door de zwaartekracht, door de plant geforceerd schuin te houden kan je een perfect rechte banaan kweken. Bovendien begint een banaan groen en eindigt hij bruin, maar zelfs als we hem paars verven, is het dan geen banaan meer? Dus hoewel geel en krom belangrijke karakteristieken zijn om de banaan van ander fruit te onderscheiden zouden we nog steeds wel een banaan herkennen als hij paars en recht was. Het gaat echter niet zo snel als het herkennen van een prototypische banaan en daar zit hem de crux. Er is een prototype van een betrouwbaar persoon in de westerse samenleving en ook een prototypisch onbetrouwbaar persoon.
Beeld je maar eens een gangmember in en daarnaast een gangster. Grote kans dat de gangmember grote gouden kettingen heeft, een afgezakte broek en zijn pistool super ineffectief schuin houdt, terwijl de gangster in een Armani-pak loopt. Die kans is groter omdat je ze tegelijkertijd moest inbeelden en dus onderscheid moest maken tussen de twee. Deze manier van objectherkenning is dus eigenlijk van nature discriminatoir, het is namelijk super effectief om in hokjes te denken. Een auto heeft 4 wielen en een fiets 2. Het is absoluut niet altijd waar, maar vaak genoeg om er gebruik van te kunnen maken. Laat dat nou ook de manier zijn waarop we computers objecten laten herkennen.
Onze hersenen zijn één groot netwerk van neuronen die met kleine elektrische signalen samen dingen beslissen. Om computers ook goed te maken in objectherkenning wordt er gebruik gemaakt van artificiële neurale netwerken. Dat werkt bijzonder goed. Zo kan Googles Vision algoritme al zonder probleem omgaan met een paarse banaan:
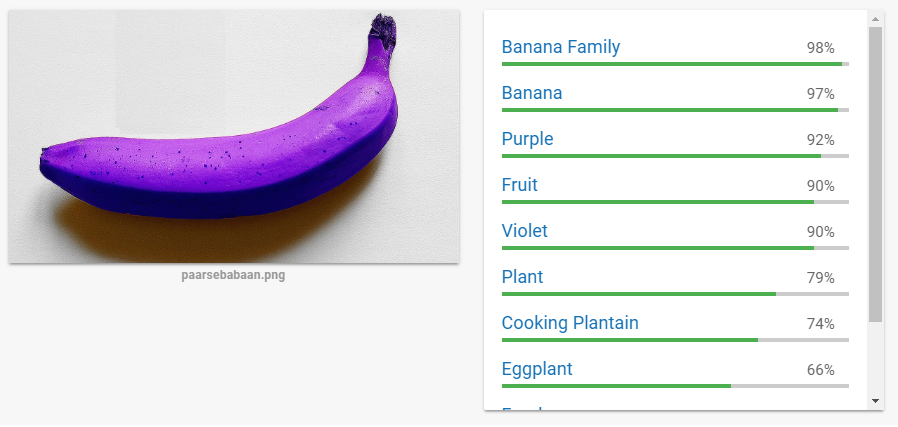
Als we het iets ingewikkelder maken door een rechte banaan te nemen en een beetje lelijk de randjes weg te fotoshoppen krijgen we het algoritme nog wel in de war:

Ik kan me echter voorstellen dat je daar zelf ook even een tweede keer naar moest kijken.
Maar als we de computers maken zoals wij zijn, en wij zijn racistisch, maken we dan niet ook automatisch racistische computers? Het zou mooi zijn als de computers “beter” worden dan wij, maar kan je iets maken dat op alle mogelijke vlakken slimmer is dan jezelf bent? Artificiële intelligentie blijft een lastig iets.
Leren programmeren animerenHet is pakweg 2 jaar geleden dat ik met deze serie ben begonnen en daarmee de missie om jou, mijn trouwe lezer te leren programmeren. In mijn tweede blog hebben we samen een spel geprogrammeerd, maar omdat we samen tot de conclusie waren gekomen dat OrcadoInvaders iets te hoog gegrepen was voor je eerste introductie tot programmeren, was dat een tekstgebaseerd_computerspel spel. Herinner je je het weer? Ondertussen heb je al heel wat meer geleerd en ook zeker niet onbelangrijk is de P5js webeditor uitgekomen. Ik vermoed dat ik P5 wel eens eerder heb genoemd; het is de JavaScript bibliotheek die ik gebruik in de meeste van mijn code voorbeelden, waaronder TicTacToe en OrcadoInvaders. P5 is gebaseerd op processing.org een organisatie die net als ik, de ambitie heeft om meer mensen te leren programmeren. Maar als ik jou was zou ik mijn blog lezen, dan krijg je tenminste ooit nog uitgelegd wat 3-waarden-logica nou precies is en hoe dat werkt.
Maar niet vandaag. Vandaag gaan we weer samen een spelletje programmeren, maar nu met graphics. Na wat overwegingen wat nou een goed spel zou zijn om samen te maken is de keuze gevallen op ‘hooghouden’, er is een heel sub genre van dit spel op bijvoorbeeld funny games, maar volgens mij zijn die allemaal in flash, en gezien flash vanwege de vele veiligheidsproblemen binnenkort in geen enkele browsers meer draait, zijn dat allemaal niet echt goede voorbeelden. Gelukkig is het spelletje heel simpel; je hebt een bal, die valt naar beneden, als je er op klikt ‘schiet’ je hem omhoog, het doel is om de bal zo lang mogelijk hoog te houden voor dat die valt. We gaan dat doen in de hiervoor genoemde P5js webeditor.
Zodra je de webeditor opent zie je links de code en als je op de play-knop drukt zie je rechts het resultaat van de code. Klik maar eens op play, je ziet rechts een vierkant verschijnen. De code die daar voor zorgt staat links onder setup en draw. Setup wordt aan het begin 1x uitgevoerd en draw elke seconde 60x. In setup wordt een canvas aangemaakt van 400 breed en 400 hoog. Ik denk graag zo groot mogelijk dus dat mag je direct veranderen in:
createCanvas(windowWidth, windowHeight);
Hiermee maken we het canvas (waar we op gaan schilderen) zo breed en hoog als in het scherm past. In draw krijgt het canvas een grijze achtergrond kleur, dat is wat saai en aangezien hooghouden een voetbal spelletje is maken we dat meteen gras groen:
background(0,180,0);
Als het goed is, is het hele rechtervlak nu groen. Mocht dat nou niet zo zijn of als je ergens verderop de draad kwijt bent, dit is het eind resultaat, kan je spieken wat er mis is gegaan.
Ok, het gras is er, nu een bal. Daarvoor gaan we een object maken (ik heb je niet voor niets leren objectificeren). P5 ondersteunt om hiervoor een apart bestand aan te maken, en dat is eigenlijk mooier, maar voor de eenvoud hou ik het even in één bestand. Eerst maken we een bal functie die als ons object gaan dienen:
function Bal(){
}
De computer moet weten hoe groot de bal is en waar die op het scherm moet worden getekend, dus daarvoor maken we variabelen aan in de functie.
function Bal() { this.diameter = 50; this.x = 0; this.y = 0; }
En de bal moet getekend worden, daarvoor maken we een functie aan:
function Bal() { this.diameter = 50; this.x = 0; this.y = 0; this.teken = function() { ellipse(this.x, this.y, this.diameter, this.diameter); }; }
In die functie staat nu dat we een ellips tekenen op coördinaten (0,0) en met de breedte en hoogte van de diameter. Aangezien een ellips met gelijke breedte en hoogte een perfecte cirkel is, gaat dit een cirkel tekenen. Om de bal te laten tekenen moeten we dit aanroepen in de draw functie. Eerst maken we de bal variabele aan in setup
function setup() { createCanvas(windowWidth, windowHeight); bal = new Bal(); }
Zodat we daarna in de draw functie hem kunnen laten tekenen.
function draw() { background(0,180,0); bal.teken() }
Er verschijnt nu een witte kwart cirkel in de linker bovenhoek, laten we hem even in het midden zetten voor het gemak, verander daarvoor in het bal object de x en y waarden respectievelijk windowWidth/2 en windowHeight/2. De bal staat nu midden in het scherm.
Nu gaan we wat leven in de bal brengen. Dat gaan we doen door zwaartekracht toe te voegen. In een hele volwassen versie van dit spel gebruiken we daarvoor een physics engine, dat is software die natuurkundige krachten nabootst, daarmee kunnen we rekening houden met het gewicht van de bal, de luchtweerstand, de gravitatie constante en dat soort dingen. Dat is echter overkill voor wat we aan het doen zijn, we gaan de bal een verticale snelheid geven, en de zwaartekracht verhoogt die snelheid neerwaarts. Eerst maar verticale snelheid aan het bal object toevoegen:
this.verticalesnelheid = 0;
En we maken een zwaartekracht functie die die snelheid beïnvloed en dan ook de y coördinaat van onze bal:
this.zwaartekracht = function() { this.verticalesnelheid += 0.2; this.y += this.verticalesnelheid; };
Dan alleen nog zorgen dat de zwaartekracht toegepast wordt elke keer als we de bal tekenen, daarvoor zetten we onder bal.teken(), bal.zwaartekracht() en voilá de bal valt naar beneden. Klein probleempje, de bal verdwijnt al snel onder de grond. Dat is natuurlijk niet goed. We zullen in onze super eenvoudige versie van een physics engine de grond de bal laten stuiteren door een opwaartse kracht toe te voegen als de grond geraakt wordt, soort derde wet van Newton zeg maar:
if (this.y + this.diameter / 2 > windowHeight) { this.y = windowHeight - this.diameter / 2; // zorg dat de bal niet vastkomt in de grond this.verticalesnelheid *= -0.8; } else { this.verticalesnelheid += 0.2; }
En hup, de bal stuitert, het verdient geen nobelprijs voor de natuurkunde, of zelfs maar een voldoende op een middelbare school toets, maar dit is soort van hoe zwaartekracht werkt, en goed genoeg voor ons spelletje.
Nu moeten we de bal nog hoog kunnen houden, dat gaan we doen door er op te klikken. P5 heeft een ingebouwde functie om muisklikken te herkennen, alle functies die P5 ondersteunt kan je vinden in de referentie. We gaan gebruik maken va de touchStarted functie, in mijn ervaring werkt het dan goed met zowel muizen als met aanraakgevoelige schermen zoals mobiele telefoons.
function touchStarted() { bal.verticalesnelheid -= 20; return false; }
Die return false wordt aangeraden in de reference dus dat doen we maar braaf. Het zal je inmiddels opgevallen zijn dat een negatieve snelheid de bal naar boven brengt en een positieve snelheid de bal naar beneden. Dat komt omdat het y-coördinaat 0 helemaal boven in het scherm ligt en het y-coördinaat met de schermhoogte helemaal onderin het scherm.
Dit werkt, alleen het maakt nu niet uit waar je klikt, dat maakt het een suf spelletje. Dit kan je nu makkelijk winnen door in je console met een interval muisklikken te genereren (je hebt immers leren automatiseren). We moeten dus kijken of er op de muis wordt geklikt. We hebben gelukkig ook de x en y coördinaten van de muis (of vinger) dus we hoeven alleen maar te controleren of de afstand tussen de muis en de bal gelijk of kleiner is dan de straal van de bal. Dit is normaal het moment dat ik me realiseer dat ik meer de straal dan de diameter gebruik en de code daar op aanpas, maar ik begin inmiddels de spreekwoordelijk prangende ogen van mijn redactrice in mijn rug te voelen gezien ik al ver over het aantal streefwoorden per blog ben (ik geef persoonlijk de ellenlange zinnen die ik maak de schuld, alsof ik een kommarecord probeer te verbreken…), dus dat mag je straks zelf doen. Dat is overigens ook de reden dat ik onze gezamenlijke flashback naar middelbare school wiskunde en de stelling va Pythagoras) oversla (ja, daar hadden we nu eindelijk een keer ‘in het echt’ gebruik van kunnen maken) en gebruik maak van de euclidische afstandsfunctie die in P5 zit ingebakken:
if (dist(bal.x, bal.y, mouseX, mouseY) <= bal.diameter / 2) { bal.verticalesnelheid -= 20; }
Op zich werkt het nu, maar het is wel een erg verticale aanpak, dat is wel heel erg agile, maar voor het spelletje niet echt leuk. Probeer zelf eens toe te voegen dat als je de bal links van het midden raakt hij naar rechts gaat en andersom (en vergeet niet van de zijkant muren te maken zodat je de bal niet kwijt raakt). Ik heb het in het eindresultaat zit, maar ik geloof dat je dit zonder spieken kan!
Als je dat gedaan hebt is het tijd voor het testen, dan blijkt dat het spelletje misschien iets te uitdagend is geworden. Met een klein beetje tweaken aan de gebruikte getallen en een scoreteller toe te voegen hebben we in de basis het spelletje. Dat valt echter ook buiten de scope van dit blog, maar dat moet je niet laten weerhouden om het zelf te doen en hoewel het het beste is om dat zonder hulp op te lossen hoeveel moeite je dat kost, kan ik me herinneren hoe frustrerend dat kon zijn toen ik net begon met programmeren, dus ook daarvoor een spiekbriefje.
Leren programmeren automatiserenIk heb lang getwijfeld over dit blog, voor de beste uitleg zou ik jullie namelijk mee willen nemen in de wereld van autohotkey (https://www.autohotkey.com/) dat is een programma waarmee je op Windows heel makkelijk een heleboel dingen kan automatiseren. Het gebruikt echter zijn eigen programmeer taal, en ik doe mijn best om al het programmeren dat ik samen met jullie doe, in javascript te doen, zodat jullie makkelijk mee kunnen blijven doen. Een aardige uitleg waarom ik jullie autohotkey wilde laten zien en waarom ik het niet heb gedaan, is dit filmpje van Tom Scott.
Een nadeel van javascript voor het uitleggen van automatisering is dat je browser veilig is gemaakt. Elke keer dat je naar een andere pagina gaat wordt je console opnieuw gestart. Dat is maar goed ook, want als dat niet zou gebeuren zou je daar vreselijk misbruik van kunnen maken. Maar dat betekent dus dat je alleen maar dingen in je browser kunt automatiseren die binnen hetzelfde scherm gebeuren. Wat je dan nog wel kunt doen is data van een andere website ophalen via een API en dat vervolgens gebruiken tijdens je automatisering. Dus mocht je straks de smaak te pakken hebben, pak mijn vorige blog er nog een keer bij.
Maar laten we iets simpeler beginnen. Het idee van iets automatiseren is dat je een taak die saai is of die je vaak moet doen, door de computer kan laten doen. Dat klinkt heel aanlokkelijk, maar het is niet altijd de moeite waard. Xkcd heeft een tabel waarin je kunt opzoeken of het zinvol is om iets te optimaliseren door het te automatiseren: (bron: xkcd.com)
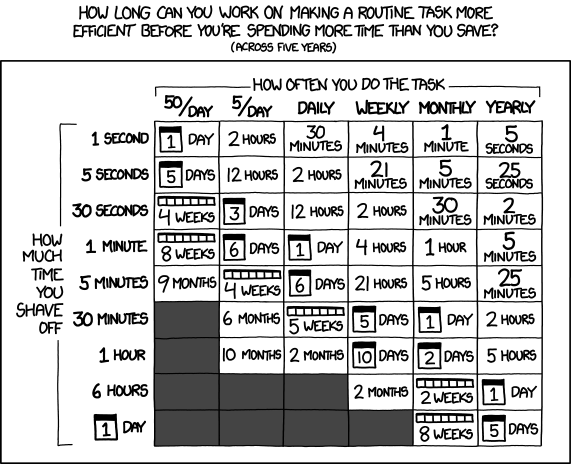
Als je er dan ook nog een andere xkcd bij pakt over automatiseren schetst dat een plaatje waarin het automatiseren van taken niet altijd de heilige graal is die het soms lijkt te zijn:

Dat neemt niet weg dat je soms door iets te automatiseren enorm veel werk door een computer kan laten doen in plaats van mensen, of de computer taken kan laten doen waar je zelf eigenlijk geen zin in hebt. Uit ervaring blijkt dat totaal fictieve onrealistische voorbeelden vaak het beste zijn, het zet de lezer namelijk aan tot zelf een realistisch scenario te bedenken. Bovendien is het voor mij het minste werk en dat is toch een beetje waar dit blog over gaat. Dus we doen een raar hypothetisch voorbeeld.
Stel je doet een online survey over een video en om te zorgen dat je de video blijft kijken en dat je niet bij je computer wegloopt moet je van de website elke 20 seconden op een knop drukken, dat reset een timer,als die timer niet op tijd gereset wordt is je aandacht er schijnbaar niet genoeg bij en krijg je niet betaald. De ethische oplossing is elke 20 seconden op de knop drukken, de makkelijkste manier, automatiseer het drukken op de knop. Hier is de site: https://undercover.horse/automatiseren/resettimer.htm
Het automatiseren van deze taak is vrij eenvoudig. Wat we willen doen is elke X seconde op de knop drukken, omdat te doen moeten we eerst weten hoe de knop heet, daarvoor kijken we naar de broncode van de site. Daarin vinden we:
<button id="btn" onclick="set20()">reset de timer</button>
Dat is makkelijk, de knop heeft een id attribuut. Javascript heeft een manier om een object te selecteren bij zijn id:
document.getElementById()
We geven het id “btn” mee en dan gebruiken we de click functie om er op te klikken:
document.getElementById("btn").click()
Dat is 1 klik, we willen het echter elke X seconden, omdat te doen kunnen we er een interval van maken:
setInterval('document.getElementById("btn").click()',5000);
Deze code zorgt er voor dat er elke 5000 milliseconden (gelijk aan 5 seconden) op de knop wordt geklikt. Als je dat in je console plakt ben je klaar, de timer komt niet meer voorbij 15.
Dit is een truc die je op elke pagina toe kan passen die een knop heeft waar je op moet klikken die niet de hele pagina ververst. Ander voorbeeld: stel je voor je wilt een kaartje kopen, om dat te doen moet je op de bestelknop op een pagina klikken. Deze wordt echter pas klikbaar op een bepaald moment. Je kan geduldig op de site wachten en toeslaan zodra de knop beschikbaar wordt, of je blijft er constant op klikken en loopt er bij weg. Hier is een demo pagina: https://undercover.horse/automatiseren/klikzsm.htm
Kleine tegenvaller, als we naar de knop kijken zien we dat hij geen id heeft:
setInterval('document.getElementById("btn").click()',5);
Dat is echter makkelijk op te lossen, als je in je console zit kan je naar het tabblad elements waar je de html van de pagina ziet staan. Als je vervolgens met je rechtermuisknop op de html code van de button klikt, kan je kiezen voor “edit as HTML” en dan kan je er zelf gewoon id=”btn” bij zetten. (Je moet buiten het edit-blokje klikken om het te bevestigen) Omdat we zo snel mogelijk willen zijn zetten we de interval waarde wat lager:
setInterval('document.getElementById("btn").click()',5);
Nu gebeurt het elke 5 milliseconden, daar kan je zelf nooit tegenop klikken. In het huidige voorbeeld is het alleen wel zo dat je al die acties binnen 20 seconden moet doen anders is de knop al beschikbaar. Als alternatief kan je ook de knop zoeken door alle knoppen te zoeken en dan de eerste uit de lijst te kiezen:
setInterval('document.getElementsByTagName("button")[0].click()',5);
Het klikken op een knop is handig, maar vaak moet je meer op een pagina doen dan alleen een knop indrukken. Gelukkig kan je met javascript een heleboel van die dingen gewoon doen. Neem bijvoorbeeld een pagina met een formulier zoals deze: https://undercover.horse/automatiseren/formulier.htm
Stel we willen blauw een heel aantal keer kiezen. Dan kunnen we het formulier een aantal keer achter elkaar invullen. Of we automatiseren het:
let y = function () { document.getElementsByTagName("input")[0].value = "Daan"; document.getElementsByTagName("input")[1].value = "Veraart"; document.getElementsByTagName("input")[4].checked = true; document.getElementsByTagName("button")[0].click(); } setInterval(y, 100);
Dit lijkt allemaal vrij triviaal, maar dit zijn dan ook nog maar hele simpele voorbeelden, die je allemaal in je browser kunt uitvoeren. De essentie is echter dat je een taak opsplitst in kleine subtaakjes en dan kijkt of je die met een stukje code kan oplossen. Dat is iets wat je bij programmeren eigenlijk heel vaak gebruikt. Alleen dan in de vorm van helper functies. Als je en stuk code meerdere keren in je applicatie hebt staan, dan kan je beter van dat stuk code een functie maken. Elke keer dat je dan dat stuk code nodig hebt, automatiseer je dat door in plaats van dat stuk code te typen, de functie aan te roepen. Bijkomend voordeel is dat als je iets aanpast in dat stuk code, het meteen op alle plekken in je programma aangepast is.
Het leukste van iets automatiseren is kijken hoe de computer voor je aan het werk is. Zo heb ik laatst het verplaatsten van Vimeofilmpjes naar Youtube geautomatiseerd. Als je het dan opstart (de foutmelding oplost waar je tegenaan loopt (voor degene die het filmpje van Tom Scott hebben gezien, het was een beetje een bodge) en nog een keer opstart) en je ziet dat hij logregel voor logregel braaf bezig is, en dan op Youtube het filmpje ziet verschijnen met dezelfde titel en omschrijving als dat het op Vimeo heeft, dat geeft een voldaan gevoel. Het is wel een klein beetje zonde dat we de tijd die we gewonnen hebben met automatiseren besteden aan het kijken naar hoe de computer het werkt doet, die hadden we beter kunnen besteden aan het uitleggen van drie waarde logica… Misschien moet ik dat maar eens proberen te automatiseren.
Leren programmeren APIreciërenBelofte maakt schuld, vandaag hebben we het over APIs. API is de afkorting voor application programming interface. Een interface gebruik je om te communiceren met een applicatie. De bekendste vorm daarvan is de GUI (graphical user interface); als je een applicatie opstart op je computer of telefoon dan is wat je ziet de GUI, het is de manier waarmee jij met de applicatie kan communiceren. Je kijkt nu naar de GUI van je browser, je kan communiceren door bijvoorbeeld te scrollen en je browser beantwoord door de pagina naar boven of beneden te verschuiven. Voor mensen is een grafische interface handig, een plaatje zegt immers meer dan 1000 woorden. Voor een computer is dat anders, die communiceert een stuk makkelijker met alleen tekst.
Nu vraag je je misschien af, hoe vaak gebeurt het nou dat een applicatie met een andere applicatie communiceert? Dat ligt een beetje aan je definitie. Als je het heel sec bekijkt, communiceert jouw browser nu met een server om deze tekst op te halen, met de driver van je scherm om het op je scherm te laten zien, met je muis of touchscreen om je invoer te registreren enzovoort. Er is dus heel veel interactie, maar we gaan het over een heel klein gedeelte hebben, want ik ratel altijd al veel te veel en anders komt er geen eind aan.
We gaan het hebben over WebAPIs, dat is waar de meeste mensen het over hebben als ze API zeggen, dus dat is wel zo makkelijk. WebAPIs zijn functies die je aan kan roepen via het internet die informatie terug geven van de applicatie waar ze voor geschreven zijn. Dat is vrij abstract, dus het is zoals altijd tijd voor een voorbeeld. Stel je wilt iemand 3-waarden logica uitleggen… Wacht ik heb jullie nog steeds geen 3-waarden logica uitgelegd en ik zit alweer boven de 300 woorden en ik ben nog niet eens begonnen met het voorbeeld, we doen wel iets anders… Stel je wilt iemand Engels leren, maar aangezien je het wel leuk wilt houden besluit je een spelletje te maken.
Het spelletje is heel simpel je pakt een plaatje, je geeft er een aantal woorden bij en dan moet er geraden worden welk woord er bij het plaatje hoort. Klinkt simpel toch? Als je er nog een beter beeld bij wilt hebben kan je het hier spelen. Ik heb het basic gehouden dus er is bijvoorbeeld geen score, maar ik heb wel een hint optie toegevoegd, want het spelletje is zonder soms niet te doen.
Voor het spelletje heb ik 2 dingen nodig, een heleboel Engelse woorden en een heleboel bijpassende plaatjes. Die kan ik natuurlijk zelf samenstellen, maar er zijn applicaties op het internet die dit al hebben dus die kan ik ook gebruiken. In dit voorbeeld gebruik ik de wordnik.com API. Wordnik is een online woordenboek en daar mag je gratis gebruik van maken. Tenminste als je het niet te zot maakt, om dat een beetje in de gaten te houden heb je een sleutel nodig om gebruik te maken van hun API, deze kan je gratis aanvragen en daarmee mag je dan een 100 aantal aanvragen per uur doen. Dus als je het spelletje heel enthousiast speelt dan zal hij het op een gegeven moment een uur niet doen. Wil je meer aanvragen doen, dan moet je daar voor betalen. De andere API is die van imgur.com, zelfde idee maar dan een plaatjes site.
We beginnen met het ophalen van 12 willekeurige Engelse woorden. Dat doen we met een API call. De Wordnik API heeft daar deze functie voor. Die roepen we aan met een URL: https://api.wordnik.com/v4/words.json/randomWords?hasDictionaryDef=true
&minCorpusCount=50
&maxCorpusCount=-1
&minDictionaryCount=20
&maxDictionaryCount=-1
&minLength=6
&maxLength=6
&limit=12
&api_key=APISLEUTEL. Deze URL vertaalt ongeveer naar: Op de v4 versie van de api.wordnik.com applicatie roepen we van de words.json functies de functie randomWords aan met een aantal argumenten. Voor de leesbaarheid heb ik alle argumenten op een eigen regel gezet. Alles achter het vraagteken zijn de argumenten waarmee ik woorden terug laat komen van 6 letters die niet super obscuur zijn. Ja, trouwe lezer, daar staat words.json. Tegenwoordig gebruikt het leeuwendeel van de WebAPIs JSON strings om te communiceren. Zoals je in het vorige blog hebt kunnen lezen zijn dat javascript objecten en dat is makkelijk want ik programmeer dit spelletje in javascript.
In de code ziet dit er zo uit:
async function laadApi() { //code niet belangrijk voor de uitleg// let wordnik_res = await fetch(url1+x); woorden = await wordnik_res.json();
Voor wie al sinds blog 1 enthousiast mee aan het programmeren is valt het waarschijnlijk op dat er ineens iets voor function staat. Het woord async geeft aan javascript aan dat er dingen asynchroon gaan gebeuren. Dit is volgens mij ook de eerste keer dat ik het gebruik, voor nu ga er maar even vanuit dat het hetzelfde is als var. De functie fetch haalt gegevens uit vanuit de url die je meegeeft. Ik geef de url van hierboven mee met mijn API sleutel. Normaal gesproken als je fetch afvuurt gaat daarna direct de volgende regel van je code af. De fetch functie kan even duren, maar daar wil je browser als het niet hoeft niet op wachten. Wij kunnen echter niet verder voor we die data hebben, dus we zeggen met het woord await tegen de browser dat hij moet wachten tot fetch klaar is voordat hij verder mag gaan met de rest van de code. Hetzelfde geldt voor de json functie, die het resultaat omzet in een javascript object. Na deze twee regels code is ‘ woorden’ dit:
[{
"id": 234698,
"word": "Yankee"
}, {
"id": 16370,
"word": "beggar"
}, {
"id": 31968,
"word": "chorus"
}, {
"id": 47154,
"word": "dental"
}, {
"id": 129143,
"word": "magpie"
}, {
"id": 133965,
"word": "miller"
}, {
"id": 81088,
"word": "patrol"
}, {
"id": 70598,
"word": "reform"
}, {
"id": 73645,
"word": "severe"
}, {
"id": 228047,
"word": "vector"
}, {
"id": 81488,
"word": "volley"
}, {
"id": 74147,
"word": "worthy"
}]
Tenminste, deze keer, elke keer dat we die code uitvoeren krijgen we andere woorden terug van Wordnik. Het is een lijst met 12 objecten, alle objecten hebben een id, een nummer waar we verder niets mee doen, en een word, het woord waar we naar opzoek waren.
Als we dat hebben zoeken we daar een plaatje bij:
woord = random(woorden).word let imgur_res = await fetch(url2+woord, { method: "GET", headers: { "Authorization": "Client-ID "+ clientID }}); plaatjes = await imgur_res.json()
Eerst pakken we een willekeurig woord uit de rij en dan geven we die mee aan de fetch voor Imgur. De Imgur API heeft de API sleutel niet in de URL staan, maar gebruikt een header voor die informatie. Een header is informatie die je browser meestuurt met een URL. Ook Imgur werkt met json dus we roepen met het resultaat de json functie aan om het bericht weer om te zetten naar een javascript object. De Imgur API geeft veel meer informatie terug dan alleen het plaatje. Zo geeft hij bijvoorbeeld ook terug hoe vaak er gereageerd is op dit plaatje, wie het plaatje heeft geüpload en wat de titel van het plaatje is. Waar we in eerste instantie in geïnteresseerd zijn is het plaatje zelf.
Tenminste als er een plaatje is. Het kan namelijk best zo zijn dat we van Wordnik een woord hebben gekregen waar Imgur helemaal geen plaatjes bij kan vinden. We moeten dus controleren of er wel plaatjes zijn, als dat zo is dan halen we de link uit het object en laten het plaatje zien waar de link naar verwijst. Vervolgens maken we linkjes van de 12 woorden die we van Wordnik hebben gekregen en zetten die er onder en het spelletje is af. Wil je de rest van de code ook zien, dan kan dat hier; ik heb er ook wat commentaar bij gezet.
Dat zijn dus WebAPIs, je vraagt aan een website gegevens door een specifieke URL aan te roepen en je krijgt die (meestal) in de vorm van een JSON string terug. Waarmee je dan vervolgens weer verder kan programmeren. WebAPIs zijn hip, dus als je denkt ‘dit is leuk!’ ik wil zelf ook wel met een API spelen, hier zijn een aantal voorbeelden van WebAPIs waar je mee kan praten.
Leren programmeren objectificerenVoordat ik dit blog ben gaan schrijven heb ik een aantal van mijn trouwe blog lezers toegezegd dat ik in mijn onophoudende missie om te laten zien dat programmeren geen magie is (voor de woordgrap is het belangrijk dat je ons wie-zijn-wij filmpje even kijkt) een blog zou schrijven over APIs. Terwijl ik daar mee bezig ben en aan het kijken wat ik daar voor uit wil leggen loop ik tegen JSON aan, wat staat voor JavaScript Object Notation. JavaScript is al wel een heel aantal keer voorbij gekomen, maar objects heb ik nog niet echt uitgelegd. In eerste instantie wilde ik een kleine paragraaf er aan wijden, maar dat voelde wat karig. Het alternatief was om het te noemen en dan later toe te lichten, maar ik moet ook ooit nog een keer 3-waarde logica uitleggen en het was eigenlijk logischer om dat eerst te doen. De APIs komen volgende keer (of de keer daarop) maar vandaag: object georiënteerd programmeren.
Misschien dat je de term object georiënteerd programmeren of de afkorting OO/OOP wel eens voorbij hebt zien komen. Object georiënteerd programmeren is een manier van programmeren, andere vormen zijn bijvoorbeeld functioneel, logisch of declaratief. De code die ik jullie tot nu toe heb laten zien is allemaal declaratief; het is een opsomming van constructies. Bij OOP ga je uit van objecten. Stel je maakt een spelletje zeg monopolie, dan is eigenlijk alles wat je vast kan houden een object: het bord, het geld, de pionnen, de kanskaarten, de straten etc. Als voorbeeld ga ik de dobbelstenen nemen, vooral omdat die vrij universeel in een heleboel andere spellen gebruikt worden.
Omdat ik geloof dat je moet blijven proberen om programmeren een beetje onder de knie te krijgen ga ik de objecten als een functie implementeren, dat is misschien niet de manier waarop de meeste tutorials het uitleggen, maar het zorgt er voor dat je de script snippets die ik straks laat zien zo in je browser console kunt plakken en uit proberen. Bovendien kan ik daarmee in een later blog heel makkelijk JSON uitleggen, maar dat is voor later. Laten we een object gaan maken.
Voor het maken van een object moeten we eerst bedenken wat de eigenschappen van dat object zijn. Voor een standaard dobbelsteen is dat een kubus met dus een 6 tal zijdes, met op die zijdes een aantal ogen oplopend van 1 t/m 6. Ook is het zo dat de som van het aantal ogen van de twee zijdes die het verst van elkaar afliggen 7 is, maar daar gaan we ons in het voorbeeld geen zorgen over maken. Eerst gaan we het aantal zijdes toevoegen.
var dobbelsteen = { aantalZijdes: 6 }
Dat was nog niet heel ingewikkeld toch? Laten we ook nog de ogen toevoegen, dat is een lijstje, dus dat zetten we tussen blokhaken.
var dobbelsteen = { aantalZijdes: 6, ogen: [1, 2, 3, 4, 5, 6] }
Als we dat in onze browser console gooien en we proberen vervolgens het 3de oog te laten zien ziet dat er zo uit:
var dobbelsteen = { aantalZijdes: 6, ogen: [1, 2, 3, 4, 5, 6] } dobbelsteen.ogen[2]; > 3
Dat komt een lijstje in JavaScript begint bij 0, dus als we het 3de element willen hebben moeten we het item uit het lijstje hebben met het nummertje 2. Nu hoor ik je denken, leuk, maar wat is hier nou het voordeel van boven:
var dobbelsteenZijdes = 6; var dobbelsteenOgen = [1,2,3,4,5,6];
Goede vraag, ik had hem zelf kunnen stellen. Een voordeel is dat je de variabelen mooi groepeert en die groepering vervolgens weer gemakkelijk ergens anders kunt gebruiken. Ook geeft het je code een gestructureerde logica, alles is een object en heeft eigenschappen. Maar een object kan meer dan alleen variabelen groeperen. Hij ondersteunt naast eigenschappen ook acties en in JavaScript zijn acties functies. Dobbelstenen moeten rollen, dus laten we een functie maken om dat te ondersteunen.
var dobbelsteen = { aantalZijdes: 6, ogen: [1, 2, 3, 4, 5, 6], dobbel: function () { return this.ogen[Math.floor(Math.random() * this.aantalZijdes)] } }
Nu kunnen we dobbelen door de functie aan te roepen als actie van de dobbelsteen:
dobbelsteen.dobbel(); > 4
Met monopolie heb je twee dobbelstenen en het aantal zetten dat je mag doen is het totaal van de twee dobbelstenen, dat is nu simpel te doen:
dobbelsteen.dobbel()+dobbelsteen.dobbel() > 7 dobbelsteen.dobbel()+dobbelsteen.dobbel() > 6
Bij de 7 gaat dit goed, bij 6 echter kan het zijn dat we dubbel hebben gegooid, namelijk 2x 3, als dat zo is mogen we nog een keer gooien, dus dat is wel belangrijk om te weten. Of een worp ‘dubbel’ is eigenlijk een eigenschap van beide dobbelstenen. Als beide dobbelstenen samen één eigenschap hebben, dan zijn ze eigenlijk samen voor ons ook een object dat bestaat uit 2 dobbelsteen objecten. Dat ziet er zo uit:
var dobbelstenen = { aantalDobbelstenen: 2, dobbelstenen: [dobbelsteen, dobbelsteen] }
Dat is wel heel vaak het woord dobbelsteen, en we mogen zelf de namen kiezen, dus laten we dit object worp noemen:
var worp = { aantalDobbelstenen: 2, dobbelstenen: [dobbelsteen, dobbelsteen] }
De worp heeft dan natuurlijk ook een actie dobbel, waar in beide dobbelstenen worden gedobbeld:
var worp = { aantalDobbelstenen: 2, dobbelstenen: [dobbelsteen, dobbelsteen], dobbel: function () { return this.dobbelstenen[0].dobbel() + this.dobbelstenen[1].dobbel() } }
Dit lost ons probleem nog niet op, maar we hebben nu de twee dobbelstenen samen, dus we kunnen nu kijken of er dubbel gegooid is, daarvoor voegen we een klein beetje extra logica toe:
var worp = { aantalDobbelstenen: 2, dobbelstenen: [dobbelsteen, dobbelsteen], dobbel: function () { let dobbel1 = this.dobbelstenen[0].dobbel(); let dobbel2 = this.dobbelstenen[1].dobbel(); let dubbelIndicator = "" if (dobbel1 == dobbel2) { dubbelIndicator = " dubbel!" } return dobbel1 + dobbel2 + dubbelIndicator } }
Dan nog even testen of het werkt.
worp.dobbel() > "6" worp.dobbel() > "11" worp.dobbel() > "8" worp.dobbel() > "4" worp.dobbel() > "12 dubbel!"
Aah ja daar is die, nou is het voor 12 natuurlijk altijd dubbel, maar we weten ook dat de 6 8 en 4 die we daarvoor hebben gedobbeld niet dubbel waren.
Nou zijn er ook dobbelstenen met een andere vorm en andere hoeveelheden ogen, in het spel D&D (Dungeons and Dragons) heb je verschillende dobbelstenen en daarmee bedoel ik dit soort dobbelstenen:

Een veelgebruikte is er één met 20 zijdes, die noem je d20 (dobbelsteen met 20 zijdes). We hebben nu het object dobbelsteen met 6 zijdes, maar we kunnen daar ook prima 20 zijdes van maken.
dobbelsteen.aantalZijdes = 20; dobbelsteen.ogen = [1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20];
Omdat we nu het bestaande object dobbelsteen hebben aangepast is dat ook meteen aangepast in het worp opject, dus als we nu de worp dobbelen kunnen we veel hogere getallen krijgen:
worp.dobbel() > "21" worp.dobbel() > "19"
Dat zijn objecten. Ergens in het begin zei ik dat dit waarschijnlijk niet de manier is waarop het in de meeste tutorials uitgelegd wordt. Wat ik nu heb laten zien is hoe je losse objecten aanmaakt door een variabele te vullen met JSON (JavaScript Object Notation.) Wat je meestal zult zien is dat er een model van een object wordt gemaakt, en dat je daar vervolgens versies van kan maken. Ik zal daar ook nog een voorbeeld van laten zien, maar daar ga ik iets sneller; ik heb het verzoek gekregen de blogs niet te lang te maken, en ik zit al weer op ruim 1000 woorden.
Wat we gaan doen is functie objecten maken, in plaats van JSON gebruiken we een functie om het object te defineren.
//standaard aantal zijdes is 6 function d(az = 6, o = []) { this.aantalZijdes = az; this.ogen = o; //als je alleen het aantal zijdes op geeft vullen we die met getallen if (o.length == 0) { for (let i = 1; i <= az; i++) o.push(i); } this.dobbel = function () { return this.ogen[Math.floor(Math.random() * this.aantalZijdes)] } }
Nu kunnen we simpel zeggen:
var d20 = new d(20);
En nu is d20 een dobbelsteen met 20 zijdes. Maar we kunnen ook een kleuren dobbelsteen maken met:
var dkleur = new d(6,["rood", "geel","groen","paars","oranje","blauw"] );
Als je dan dobbelt krijg je één van die kleuren terug.
dkleur.dobbel() > "blauw"
Dat kunnen we dan natuurlijk ook voor de worp doen:
function w(ds, aantal = 0) { //als er 1 dobbelsteen wordt meegegeven vul het lijstje met aantal stuks er van if (aantal > 0) { this.dobbelstenen = []; for (let i = 1; i <= aantal; i++) this.dobbelstenen.push(ds); } //anders gebruik de opgegeven dobbelstenen else this.dobbelstenen = ds; this.dobbel = function (show = false) { let totaal = 0; let resultaat = "" for (d of this.dobbelstenen) { let ogen = d.dobbel() totaal += ogen; resultaat += ogen + "+"; } resultaat = resultaat.substr(0, resultaat.length - 1); resultaat += "=" + totaal if (!show) resultaat = "" + totaal return resultaat; } this.dobbelShow = function () { return this.dobbel(true); } }
In D&D kan je een spreuk doen die 8d8 aan schade doet (Je moet dan 8 keer met een dobbelsteen met 8 zijdes rollen en het totaal optellen, Dungeons and Dragons ga ik verder niet uitleggen hoor, dat moet je maar een keer bingen), als we dat in onze object georiënteerde functies willen doen kans dat nu zo:
var d8 = new d(8); var w8x8 = new w(d8,8) w8x8.dobbelShow() > "3+1+8+8+7+3+7+6=43" w8x8.dobbel() > "30"
Dat zijn kort samengevat objecten. Ik heb het voorbeeld gegeven van dobbelstenen, maar deze techniek kan je voor vrijwel alles toepassen. Kleine tip: als je mensen of dieren objectificeert, zorg dan wel dat je dat alleen tijdens het programmeren doet, sommige dingen vertalen slecht naar de echte wereld.
APEX 18.1Oracle APEX 18.1
Oracle apex 18.1 is inmiddels alweer twee maanden beschikbaar; hoog tijd dus om er eens iets over te schrijven. Met deze nieuwe versie van APEX heeft het team achter APEX wederom een flinke stap gezet om het leven van de ontwikkelaars gemakkelijker te maken. Ik zal een aantal grote nieuwe/aangepaste features benoemen, los daarvan zijn er natuurlijk ook nog heel veel kleine aanpassingen gedaan.
Application Builder
In de application builder zijn de wizards aangepakt waardoor ze slimmer zijn geworden en er minder stappen nodig zijn om diverse componenten te maken. De nieuwe create app wizard (APEX blueprint) is echt een nuttige toevoeging. Je kan met deze wizard op een simpele manier een nieuwe applicatie maken zonder één regel code te gebruiken. Bij de property editor is een zogenaamd “sticky filter” gekomen, hierdoor kan je de filter waarden vasthouden. De algemene zoekfunctie is tevens verbeterd deze lijkt nu op de veel gebruikte spotlight search op een Mac computer. Op één plek zoeken binnen de gehele APEX applicatie.
REST
Er zijn diverse verbeteringen en toevoegingen aan de REST functies van APEX gedaan. Zo is er nu REST enabled SQL support, met behulp van de feature kan je SQL statements laten uitvoeren in een andere database met behulp van HTTP en REST. Het resultaat krijg je vervolgens aangeleverd in JSON formaat. Je hoeft dus geen database link meer te gebruiken. Je kan zelfs grafieken, reports en andere APEX componenten maken met behulp van deze functie. Ook kunnen er andere REST services gebruikt worden binnen de APEX applicatie. Binnen APEX is nu een complete REST Workshop gekomen. Hier kan je zelf je REST services definiëren en onderhouden. Van deze services kan je vervolgens ook documentatie laten genereren met één click.
Grafieken
De Oracle JET engine is geüpgraded naar version 4.2. Met JET kan je binnen APEX de mooiste grafieken maken die gebaseerd zijn op HTML5, CSS3 en JavaScript. Een aantal nieuwe grafieken zoals Gannt, Box-Plot en Pyramide zijn toegevoegd.
Mobile ontwikkeling
Ontwikkelen voor mobiele devices was natuurlijk al prima te doen met het Universal theme. Hier is echter ook weer een flinke stap gezet door een aantal componenten die regelmatig gebruikt worden in een mobiele UI zoals Listview, Column Toggle en Reflow Report standaard beschikbaar te maken in dit theme. Tevens zijn er nog een aantal wijzigingen in het Universal theme doorgevoerd specifiek voor mobiele devices zoals pagina headers en footers die meer consistent worden weergegeven. Wellicht de beste toevoeging voor mobiel ontwikkelen is dat er nu standaard support is voor touch based dynamic actions. Je kan nu dus dynamic actions maken voor acties zoals dubbel tikken, vegen en zoomen.
Toegankelijkheid
De manier waarop een applicatie toegankelijk gemaakt kan worden voor minder validen is veranderd. De link onderaan de pagina om om te schakelen naar de toegankelijk modus is verdwenen. Het is de bedoeling dat de applicatie meer wordt ontworpen en gebouwd volgens de regels die opgezet zijn door de W3C organisatie. Om de ontwikkelaar te helpen om dit op een juiste manier te doen, is de APEX advisor uitgebreid zodat deze ook kan testen of je applicatie wel voldoende toegankelijk is voor minder validen.
Font APEX
Font apex is een collectie van meer dan 1000 iconen die je kan gebruiken binnen je applicatie. Deze set is voor APEX 18.1 onder handen genomen o.a. door van alle iconen een 32×32 pixel versie toe te voegen.
Authenticatie
In APEX 18.1 is er een nieuwe authenticatie schema bij gekomen, het zogenaamde social sign-in schema. Hiermee is het voor ontwikkelaars mogelijk om authenticatie op te zetten voor o.a. Oracle Identity Cloud Service, Google, Facebook en generiek OAuth2. Dit alles zonder extra code!
Interactive Grid
De interactive grid is ook onder handen genomen en begint meer en meer excel achtige functies te krijgen. Dit is voor de gebruikers natuurlijk super handig maar ook aan de ontwikkelaars is gedacht. De API van de interactive grid geeft je de mogelijkheid om deze naar eigen believen uit te breiden. Extra menu’s, buttons of processen het kan allemaal. Om hier goed mee om te kunnen gaan loont het wel om je eerst, in ieder geval een beetje, te verdiepen in de architectuur van de interactive grid.
API
Nu de term API is gevallen kan ik daar nog aan toevoegen dat de JavaScript API’s aangepast en uitgebreid zijn. Dus nog meer info om je applicaties te kunnen tweaken!
Er valt natuurlijk nog veel meer te vertellen over deze nieuwe versie maar ik denk dat ik nu wel genoeg redenen heb gegeven om APEX 18.1 snel uit te proberen. Mocht je dit nog niet gedaan hebben maak dan een account aan op apex.oracle.com om met deze versie wat ervaring op te doen.
Of download en installeer het in je eigen omgeving want dat kan natuurlijk ook!
Eventual consistency
Ik ga snel weer eens een blog schrijven zou ik lang geleden wel eens gezegd kunnen hebben. Dat zou dan inconsistent zijn met wat er hier op de site te zien is geweest.
Inconsistent zien we als een vies woord, het is een soort onwaarheid. Het ene zegt dit en het andere dat, er is er een die liegt!
In dit specifieke geval zou het meer een onverstandige belofte zijn, maar het had ook een technische reden kunnen hebben. Deze blog zou ik misschien een paar maanden geleden al geschreven kunnen hebben en vanwege een defecte communicatie nooit doorgekomen zijn. Wat je ziet is dan niet in sync met wat er geschreven is. Zou dat gebeurd zijn en de communicatie was hersteld dan zou je ineens een nieuwe blogpost met een datum ver in het verleden kunnen zien. Ziet er niet heel betrouwbaar uit, maar is in dit geval ook niet ernstig.
Dit soort situaties komen steeds vaker voor in systemen. Niet in de tijd van maanden zoals in dit (overigens zuiver hypothetische) voorbeeld, maar eerder in seconden of minuten. Dit heeft te maken met de meer gedistribueerde systemen die tegenwoordig ontwikkeld worden. De achtergrond zit hem in het zogenaamde ‘twee generaals probleem‘.
Het probleem is dat de generaals geen aanval kunnen coördineren als ze niet zeker zijn dat hun communicatie snel en volledig is. De generaals zijn in ons vakgebied computers en de communicatie loopt over een netwerk. Wil je zorgen dat alle betrokken systemen op elk punt in tijd hetzelfde laten zien dan is de consequentie wachten. Binnen een fysieke machine kan dat en dat is ook wat we gewend zijn te doen. Over een netwerk kan er verlies zijn en met gedistribueerde systemen als microservices kun je wel eens niet weten hoe vaak een stuk software waar draait.
Het gevolg is inconsistentie. Bah, ondanks de uitleg toch nog steeds niet leuk.
Je bent bijvoorbeeld een huisje aan het boeken voor de vakantie en even later blijkt dat de periode toch niet beschikbaar was. Van een systeem vinden we dit al snel een defect, maar in de buitenwereld speelt hetzelfde en zien we het als normaal. In een restaurant bestel je de dagschotel tonijn en even later komt de ober terug met de mededeling dat zojuist het laatste stuk tonijn gebruikt is en dat het toch iets anders uitzoeken wordt.
De vroegere systemen hadden als nadeel dat als het uitviel je niets had of je moest hele dure oplossingen voor failover en disaster recovery inrichten. Ook werd het heel snel heel duur als je op wilde schalen. Gedistribueerde systemen garanderen betere availability, maar er kunnen zogenaamde partitions ontstaan als er een een onderdeel niet bereikbaar is. Deze partitions zijn dan onderling niet meer consistent. We leveren dus consistentie in voor beschikbaarheid en in het kielzog daarbij winnen we snelheid en schaalbaarheid.
Om het voordeel te pakken en zo min mogelijk last te hebben van de consequenties is het zaak om gedistribueerde systemen slim op te zetten. Enerzijds vanuit de functionele hoek. Hoe ga je om met de verschillende inconsistente situaties? Hier is het zaak om zoveel mogelijk naar de buitenwereld te ontwerpen en vergelijkbare afhandelingen voor het systeem te bedenken.
Daarnaast moet de inconsistentie tijdelijk blijven, uiteindelijk moet alles weer kloppen. De oplossing daarvoor is werken met een patroon als ‘event sourcing’. Als je alle handelingen in de tijd wegschrijft in een centrale log dan is daaruit altijd weer te bepalen hoe elke situatie uitpakt ook al komt er iets te laat door. Zo kunnen de systemen op de achtergrond zelfherstellend zijn.
Stel je bijvoorbeeld de situatie van een bibliotheek voor. Je kunt in een database bijhouden welk boek aan wie uitgeleend is, maar als het terugbrengen eens niet goed verwerkt is blijft het boek uitgeleend staan. Als je het dan opnieuw uitleent staat de nieuwe klant geregistreerd bij het boek. Komt daarna de actie van het terugbrengen door dan kun je niet meer goed zien of het te laat ingeleverd is. Werken met een log als basis geeft je dan de mogelijkheid om elk punt in de tijd te reconstrueren en af te handelen.
De eigenlijke persistentie (opslag) ligt bij event sourcing niet meer zoals gebruikelijk in een database, maar in deze log. Dit levert weer andere voordelen. Dat is wellicht iets voor een andere keer, maar het kan even duren voor dat doorkomt.
Leren programmeren (de)coderenHeb je weleens dat je iets tegen iemand wilt vertellen, maar dat je niet wilt dat iemand anders het hoort. Dan ben je absoluut niet de enige. De simpelste oplossing is zorgen dat niemand je kan horen, maar stel dat dat geen optie is. Je wilt nog steeds iemand anders iets vertellen, dus moet je een andere oplossing hebben. Mocht je nou je publiek kennen, dan kun je in een taal spreken die de rest van de aanwezigen niet kent, of zoals ouders bij jonge kinderen nog wel eens doen, het woord spellen. Om zeker te weten dat niemand anders de taal spreekt die jij en je buddy spreken, kan je codetaal gebruiken, een niet bestaande taal die je samen hebt afgesproken. In theorie kun je dan naar hartenlust kletsen zonder dat iemand anders je begrijpt. In theorie, want als je dat te lang doet waar een kind van ongeveer 2,5 bij is dan spreekt die voor je het weet dezelfde codetaal vloeiend.
Het internet bestaat uit talloze computers die constant met elkaar praten en een onbekend aantal mensen dat continu mee (probeert te) luisteren. Nou is dat niet zo erg als iemand dat doet terwijl je dit blog leest, immers lezen zij dan ook dit blog, dus dat is eigenlijk een win-win situatie. Maar als iemand met je meeleest tijdens het invoeren van je wachtwoord of bekijken van je mail, is dat een heel ander verhaal. Daarom wordt er steeds meer druk gezet door grote bedrijven als Google en Apple om verbindingen te versleutelen. Je zult het vast wel in de communicatie van bijvoorbeeld je bank hebben gehoord: “let op het groene slotje in je browser”. Het coderen en decoderen gaat vanzelf, je merkt daar verder dus niet zoveel van. Zo zijn dit en dit exact de zelfde pagina, op dezelfde server. Alleen is in het ene geval het verkeer versleuteld en in het andere niet.
Dat het soms wel handig is dat je communicatie niet zomaar afgeluisterd kan worden was voor dat het internet bestond ook al wel duidelijk. De Romeinse keizers moesten bijvoorbeeld wel eens bericht sturen naar de uiteindes van hun rijk. Dat ging in die tijd per bode. Als die berichten over troepenverplaatsingen gingen dan was het wel zo handig dat de Galliërs dat niet te weten kwamen. Maar de Galliërs waren ook niet gek, dus die probeerden zo’n bode te onderscheppen. Om te voorkomen dat de Galliërs iets met de brief konden, versleutelden de Romeinen hun teksten met een Caesarcijfer (de naamgeving is niet geheel toevallig). Een Caesarcijfer werkt als volgt. Je neemt een tekst en neemt voor alle letters een getal verderop in het alfabet. Bijvoorbeeld stel je hebt het woord: Orcado en je neemt een Caesarcijfer met 1 verplaatsing. De O wordt dan een P, de r een s, de c een d, de a een b, de d een e en de o weer een p. De versleutelde tekst is dan Psdbep. En als de generaal aan het front de tekst wilde lezen deed hij hetzelfde maar dan andersom. Een populaire versie hiervan is ROT13 dit is een Caesarcijfer met een verschuiving van 13, dit zorgt er voor dat coderen en decoderen hetzelfde resultaat geeft. Dit heeft heel lang prima gewerkt. Maar dit is niet een hele moeilijke versleuteling en als je het trucje kent is de tekst decoderen een kwestie van maximaal 25 keer proberen.
Daarom werd er een goede 1500 jaar later een iets ingewikkeldere versie bedacht, het Vigenèrecijfer. Het Vigenèrecijfer lijkt erg op het Caesarcijfer, het enige verschil is dat de sleutel langer is. In plaats van dat we voor elke letter dezelfde verschuiving in het alfabet gebruiken, wordt de verschuiving voor elke letter bepaald door een code woord. Laten we als voorbeeld opnieuw Orcado versleutelen maar nu met sleutel “blog”. De eerst letter is de o, de eerste letter van de sleutel is de b, dat is het tweede letter in het alfabet, daarom verschuiven we de o één plaats naar boven. Ja dat is een kleine instinker, we beginnen met tellen bij 0, dus je moet overal 1 van af halen. Maar de O wordt dus weer een P. De r wordt versleuteld met de l deze wordt dus 11 plaatsen verschoven, dan kom je 3 plaatsen voorbij de z dus beginnen we weer vooraan het alfabet en wordt het de letter c. De c versleutelen we met de o, dat wordt een q, de a met de g dat wordt een g. Nu zijn we aan het einde van de sleutel, maar we moeten nog cijfers versleutelen, daarom beginnen we de sleutel opnieuw, de d versleutelen we met de b, dat wordt een e en tot slot versleutelen we de o met de l en dat wordt een z. De versleutelde versie wordt dus Pcqgez. Dit was in de 16de eeuw toen dit cijfer bedacht is erg ingewikkeld om mee te werken, maar met computers is het maar 10 regels code en voor als je er mee wilt spelen heb ik die hier voor je geschreven. Om het lastiger te kraken te maken worden hoofdleters en spaties niet ondersteund.
Dat is een heel stuk moeilijker te kraken, want van de 25 opties die we eerst hadden, zijn het er nu heel veel meer. Maar als je een korte sleutel gebruikt en een tekst van een paar zinnen, dan is het nog wel te kraken, tenminste met een computer, met de hand is het niet te doen. Wat je namelijk kan doen is alle combinaties proberen en dan de computer laten kijken wat bij elke mogelijke sleutel de letterfrequentie is. De top 3 in het Nederlands is:
1. E 19,06%
2. N 9,91%
3. A 7,66%
Als je sleutel een tekst geeft waarbij deze letters ongeveer in deze frequenties voorkomen dan is er een grote kans dat dat de goede sleutel is. Je kunt ook nog extra statistische analyse doen op herhalingen en patronen in de versleutelde tekst om de lengte te kunnen schatten, maar als de sleutel onder de 10 karakters is kan een computer zonder probleem alle combinaties uitproberen van alle lengtes. Hoe langer je sleutel hoe veiliger het is, maar ook hoe moeilijker te onthouden. Een truc is om iets met meerdere codes te versleutelen. Als je zorgt dat de lengte van de sleutels priemgetallen (ik had het beloofd en hier zijn ze dan hoor) zijn, dan wordt je effectieve sleutel zolang als de lengtes keer elkaar. Als je een sleutel van 11 en eentje van 13 hebt dan wordt je effectieve sleutel 143 karakters lang. Dit werkt alleen met priem getallen, als je een sleutel hebt van 20 en een sleutel van 30 dan in je effectieve sleutel maar 60 karakters lang, immers is 60 mooi deelbaar door beide. De versleutelde tekst in het vorige blog is versleuteld met een Vigenèrecijfer en een code van minder dan 8 letters, dus mocht je het nog niet gekraakt hebben, maar zou je dat wel graag willen, heb je bij deze de informatie die je nodig hebt om dat alsnog te doen.
Computers gebruiken geen Vigenèrecijfer om de communicatie over het internet te versleutelen en dat is niet omdat het onveilig is. Er is namelijk een versie van het Vigenèrecijfer dat onkraakbaar is. Dit is het Vernamcijfer, een Vernamcijfer is een Vigenèrecijfer waarbij de sleutel minstens zolang is als de versleutelde tekst en de sleutel bestaat uit willekeurige letters. Immers als je de versleutelde tekst “abcdef” hebt kan dit “orcado” zijn met als sleutel “mkadbr”, maar ook “blogje” met sleutel “zqoxvb” of “decode” met sleutel “xxapbb”. Het zou in de context allemaal kunnen dus je hebt geen enkele mogelijkheid om uit te vinden welke de goede is. Nee de reden is praktisch, om dit soort versleuteling te gebruiken moeten zowel de zender als de ontvanger de sleutelcode weten. Jij en ik kunnen dat een keer als we bij elkaar zijn afspreken, maar computers op het internet hebben die luxe niet. Die moeten dat over het internet doen, maar dan kan iedereen meeluisteren. Want voordat je een sleutel hebt afgesproken is de communicatie onversleuteld. Een klassiek voorbeeld van een kip-ei-probleem. Gelukkig is daar een oplossing voor.
Voor internet communicatie wordt er gebruik gemaakt van asymmetrische versleuteling. Bij asymmetrische versleuteling heb je 2 sleutels, eentje om tekst te versleutelen en eentje om tekst te ontsleutelen. Die twee sleutels zijn een publieke en een geheime sleutel. Iedereen mag de publieke sleutel weten. De geheime sleutel weet alleen de eigenaar van de geheime sleutel. Iedereen die de publieke sleutel heeft kan nu een tekst versleutelen, de eigenaar van de geheime sleutel is de enige die dit kan ontsleutelen. Wat je nu kunt doen is dat je tegen een webpagina zegt: “hier dit is mijn publieke sleutel”. De webpagina verstuurt vervolgens alles naar je toe versleuteld met die sleutel en omdat jij de enige bent met de geheime sleutel kan niemand anders het lezen.
Het heeft ook nog een tweede voordeel. De webpagina kan namelijk ‘bewijzen’ dat hij echt de webpagina is die hij zegt te zijn. Dat doet hij door een stuk tekst van jouw keuze te versturen dat hij versleuteld heeft met zijn eigen geheime sleutel. Omdat het niet uitmaakt wat de versleutel sleutel en wat de ontsleutel sleutel is, kan je dat certificaat nu ontsleutelen met de publieke sleutel die je ook van de webpagina krijgt. Omdat de enige tekst die je kunt ontsleutelen met de publieke sleutel, tekst is die versleuteld is met de geheime sleutel die er bij hoort, weet je zeker dat de webpagina de eigenaar is van de geheime sleutel. Het enige wat je dan nog hoeft te doen is bij een instantie die certificaten uitgeeft navragen of die publieke sleutel bij die website hoort en je weet zeker dat je met de goede website praat.
Nu hoor ik je denken, “ok dat was crisis vaak het woord sleutel, maar ik heb het idee wel ongeveer begrepen, maar hoe werkt dat dan twee sleutels hoe kan je tekst met een sleutel versleutelen met een andere ontsleutelen?” Goede vraag, het antwoord is een stukje wiskunde met priemgetallen (daar zijn ze weer) en de modulo. Het gaat me iets te ver om uit te leggen hoe die wiskunde precies werkt als je het wilt weten kan je op RSA bingen er zijn genoeg sites die je dat kunnen uitleggen. Of als je niet van priemgetallen houdt kun je ook bingen op Elliptic-curve cryptography (ECC) maar ik kan je niet beloven dat de wiskunde er veel makkelijker van wordt. Wat ik wel zal doen is een getallenvoorbeeldje.
Stel je wilt het getal 12 versleuteld naar mij toe sturen. Ik geef je de publieke sleutel 3 en 55, wat jij doet om het bericht te versleutelen is (12^3)%55 dat is 12 tot de macht 3 en dat dan modulo 55. Dat geeft eerst 12^3 = 1728 en als we dat modulo 55 doen blijft er 23 over. We kunnen van die 23 met de twee sleutels die we hebben 3 en 55 niet meer terug naar 12 er is immers geen manier om te achterhalen hoe vaak ik 55 bij 23 moet optellen voordat ik de derde machtswortel er uit mag nemen. Ik heb echter de geheime sleutel die hier bij hoort, namelijk 27. Wat ik doe is (23^27)%55 en voila dat is 12.
Nou was het Vernamcijfer onkraakbaar, dat is bij vrijwel alle gangbare cijfers echter niet het geval, het vorige voorbeeld is een (versimpelde) vorm van RSA een van de meest gebruikte encryptie op het internet. Van RSA wisten de makers vanaf het begin al dat het te kraken was en hoe, de reden dat het toch nog veilig is, is omdat het kraken heel veel rekenkracht kost. Het getal 55 uit het voorbeeld is een vermenigvuldiging van 2 priemgetallen, als je er achter kan komen welke 2 priemgetallen kan je de geheime sleutel zo uitrekenen. In dit voorbeeld is dat heel goed te doen, degene onder jullie die vlug zijn met rekenen zullen al snel gezien hebben dat dat 5 en 11 zijn. Vanaf daar is het simpele wiskunde (namelijk (5-1)*(11-1) = 40, -39%40 = 1, -39/3 (de publieke sleutel) = -13 en -13%40 = 27. Voor meer uitleg moet je echt RSA even bingen. Bij 55 is dat goed te doen, maar voor RSA zijn dat zulke grote getallen dat het enorm veel rekenwerk is om die 2 priemgetallen te achterhalen en dus is het veilig. Als er ooit iemand iets slims bedenkt om snel die 2 priemgetallen te kunnen achterhalen is alle met RSA versleutelde data simpel te ontsleutelen.
Een alternatief voor asymmetrische versleuteling is een geheime sleuteluitwisseling. Ik heb net al heel wat wiskunde gedaan dus ik zal dit idee uitleggen met een analogie die daar vaker voor gebruikt wordt, verf. Stel je wilt een geheime kleur verf afspreken met elkaar terwijl iemand al je communicatie over de verf afluistert. Het voordeel dat je hebt is dat als je twee kleuren verf mengt dat het heel lastig is om vanuit de gemengde verf de oorspronkelijke kleuren te achterhalen. Stel je voor dat je een pot blauwe verf hebt en je wilt eigenlijk paarse verf. Je voegt er op gevoel rode verf bij tot je een mooie kleur paars hebt. Je verft je muur paars en bijna op het einde merk je dat je te weinig verf hebt. Gelukkig heb je nog een pot blauwe verf en je hebt de paarse verf als voorbeeld. Je weet alleen niet meer welke tint rode verf je gebruikt hebt en niet hoeveel. De klussers onder jullie hebben iets dergelijks mogelijk al een keer meegemaakt en zullen je verzekeren dat het schier onmogelijk is. Dat is doffe ellende voor je paarse muur, maar voor ons komt het goed uit. Wat je doet is je spreekt met de ander een basiskleur af, bijvoorbeeld 1 liter blauwe verf. Vervolgens voeg je allebei je in het geheim je eigen kleur toe. Jij doet rood en maakt het dus paars, de ander doet geel en maakt het dus groen. Vervolgens stuur je elkaar jullie nieuwe kleuren. Daar voeg je je eigen geheime kleur aan toe en je hebt allebei een paars-groene kleur die iedereen die jullie combinatie kent wel ongeveer kan nabootsen, maar net niet precies.
Hoewel het internet steeds meer leunt op versleuteling en je bij bijna elke website een groen slotje ziet, is het allemaal gebaseerd op versleuteling waarvan we weten dat het te kraken valt. Er is ook al een heel aantal standaarden dat we een paar jaar geleden nog gebruikten dat nu niet meer als veilig wordt beschouwd. Het is een gevecht tussen de rekenkracht aan de ene kant en het nog zwaarder te berekenen maken aan de andere kant. Wat in ieder geval niet veilig is, is het Vigenèrecijfer met een te korte sleutel. Heb jij het al gekraakt? Als je nog meer hulp nodig hebt, hier een opzetje. En als je nou de smaak te pakken hebt en ook een snel algoritme hebt bedacht om RSA of ECC te kraken, stuur me dan even een mailtje.
Leren programmeren optimaliserenAls je weleens op je telefoon kijkt bij je apps welke wijzigingen er in al die updates zitten zie je meestal 3 dingen: bugfixes, tweaks en improvements. Bugfixes spreekt redelijk voor zich, er zaten kleine fouten in de software en die zijn er nu uit. Tweaks en improvements is echter wel erg vaag. Het zijn verbeteringen in de code, maar er was niks stuk. Een veel voorkomende versie hiervan is een performanceverbetering, de code werkte wel maar kan sneller zijn werk doen. Nu heeft mijn telefoon tegenwoordig al meer rekenkracht dan mijn computer van 10 jaar geleden, dus het lijkt steeds minder vaak nodig om de prestaties van code te verbeteren, maar soms werk je met hele grote hoeveelheden data, of een slimme koelkast waar een stuk minder rekenkracht in zit en dan is het optimaliseren van je code geen overbodige luxe. Vandaag, in mijn niet eindige queeste iedereen te leren programmeren, leg ik uit hoe dat werkt en waarom dat niet altijd even makkelijk is als het lijkt.
Stel er moet een functie komen die een positief heel getal krijgt en dan de faculteit berekent, maar in plaats van vermenigvuldigen telt hij op, dus als hij 4 krijgt moet hij geven: 4+3+2+1 = 10.
Dat zou je op de volgende manier kunnen doen:
var y = function(getal) { if (getal == 1) return 1 else return getal + y(getal - 1) }
(Wacht dit voelt als plagiaat, alhoewel ik kopieer het wel letterlijk, maar het is uit mijn eigen blog “leren controleren” is het dan nog steeds plagiaat? Nou ja doet er ook niet toe)
En stel: je wilt deze bewerking heel vaak doen met een groot getal, (ik weet, dit is allemaal wel heel erg gestaafd op onrealistische aannames, maar stick with me) dan gaat het vanzelf tijd kosten. Om dat te laten zien bereken ik 20.000 keer de totaal waarde van y(11000):
var x = new Date(); for (var i = 0; i<20000;i++) y(11000); new Date() -x; > 3372
Wat ik hier doe is: neem de huidige tijd, sla die op, voer de functie 20.000 keer uit met het getal 11.000, kijk hoe laat het nu is en trek daar de eerder opgeslagen tijd vanaf. Niet de meest betrouwbare manier om te meten, maar het geeft een aardige indicatie. Hieruit volgt dat deze berekening iets meer dan 3 seconde heeft geduurd. Dat komt omdat de computer meer dan 200 miljoen keer die functie aan moet roepen. Als je het zo bekijkt valt 3 seconde nog wel mee. Maar we hadden ook een versimpelde versie van de functie gevonden:
var z2 = function(getal) { return (getal * (getal + 1)) / 2 }
We proberen met die functie precies hetzelfde:
var x = new Date(); for (var i = 0; i<20000;i++) z2(11000); new Date() -x; > 4
Dat is bijna een factor 1.000 verschil. Nu zijn dit totaal onzinnige waardes. Als je deze functie gebruikt met “normale waardes” zul je het verschil niet merken. Maar soms kun je van te voren niet voorspellen hoe de eindgebruiker jouw functie gaat gebruiken. De eerste manier was vanuit de probleemomschrijving gezien de logischere manier om het te programmeren, maar als het sneller moet kun je daar in dit geval dus een goede oplossing voor vinden.
Kom, we doen er nog eentje. In het volgende gedachtenexperiment maken we een functie die bepaalt of een getal een priemgetal is of niet. Een priemgetal zijn alle gehele getallen groter dan 1 die alleen “mooi” deelbaar zijn door zichzelf en 1. Ik zou zeggen: “Schrijf zelf even de code”, maar ik heb geen tijd om op jouw oplossing te wachten, dit blog moet af, dus hierbij mijn oplossing:
var p = function (getal){ for (var i = 2;i<getal;i++){ if(getal%i == 0) return false } return true; }
Moet ik die code nog uitleggen? Ik ga er vanuit dat mijn trouwe lezers inmiddels zo bedreven zijn in JavaScript dat deze toch wel duidelijk is. Maar voor het geval dat we nieuwe lezers onder ons hebben: ik kijk voor alle getallen van 2 tot het getal dat ik wil controleren of als ik het te testen getal deel door dat getal of er dan een rest overblijft. Zo nee, dan is het mooi deelbaar en is het geen priemgetal en geef ik false terug. Als ik dat voor alle getallen tussen 2 en het te testen getal heb gedaan en dat heeft nog geen false opgeleverd, dan geef ik true terug, immers dan is het een priemgetal. Even snel testen in de browser, werkt als een trein, niets meer aan doen.
Voor de helft van de getallen (alle even getallen) gaat dit kneiter snel. Maar ook met een priemgetal zoals 104.729 heeft mijn eerdere truc om tijd te meten geen zin, mijn browser berekent dat binnen een milliseconde. Echter als we een iets hoger priemgetal pakken zoals 982.451.653 dan doet hij er ineens 7 seconde over. Dat is dan wel weer lang. Kortom we moeten proberen het proces iets te versnellen. Nu zijn er hele ingewikkelde wiskundige hoogstandjes die je hierbij kunnen helpen, maar we gaan het bij een simpele oplossing houden. We gaan de zoekregio verkleinen. Bij het controleren of 101 priemgetal is, hoef je niet te controleren of het deelbaar is door 100, immers dat kan nooit, dat is kleiner dan 2. Daar kan nooit een mooie deling uit komen. Sterker nog alles boven de 50 is kleiner dan 2, dus die kunnen we vergeten. Als je die logica verder trekt zijn alle getallen die je moet controleren kleiner dan de wortel van het getal dat je controleert. Dat is een kleine aanpassing:
var p2 = function (getal){ for (var i = 2;<=Math.sqrt(getal);i++){ if(getal%i == 0) return false } return true; }
Als we het nu nog een keer testen met 982.451.653 duurt het nog maar 9 milliseconde. Dat is weer een orde van grote verschil van 3. Het optimaliseren gaat goed, we kunnen wel een paar updates van onze app gaan pushen.
Waarom zei ik in het begin eigenlijk dat het moeilijk was? Dit ging super soepel. Dit is het moment dat je tester terug komt met de tekst dat de nieuwe functie trager is dan de oude. Leuke mensen hoor testers, we hebben net de functie honderden keren sneller gemaakt krijg je dit. Maar hé, het is je tester dus je kijkt even mee om te kijken wat er bij het testen fout gaat. Bij het testen is niet 982.451.653 maar 982.451.654 gebruikt en is de functie een paar keer achter elkaar gedraaid:
var x = new Date(); for (var i = 0;i<200000000;i++) p2(982451654) new Date() -x; > 2604
Bij de oude functie duurt dit 1625 milliseconde, bij de nieuwe 2604, de nieuwe functie is dus ruim anderhalf keer zo traag. Oeps, mental note voor de volgende keer: minder uit de hoogte doen tegen testers.
Wat gaat er mis? We hadden de functie toch sneller gemaakt? Voor grote priemgetallen is het inderdaad een stuk sneller. Hij hoeft namelijk veel minder getallen te controleren. 982.451.654 is echter geen priemgetal, het is namelijk deelbaar door 2. 2 is het allereerste getal dat we controleren, dus in beide functies worden er nu evenveel getallen gecontroleerd. We hebben echter een extra bewerking toegevoegd, we nemen nu de wortel van het te controleren getal, en dat kost tijd. Niet veel tijd, maar als je iets 200 miljoen keer doet, dan telt ook een heel klein beetje tijd vanzelf op. Je hebt de functie dus sneller gemaakt, maar ook trager gemaakt. (Ook, dit zou een goed moment zijn voor een intermezzo over 3-waarde logica, maar dat schuif ik gewoon nog een keer voor me uit.)
Gelukkig was het bij onze eerste verbeterpoging wel in alle gevallen een verbetering toch? De formule zal toch zeker wel sneller zijn dan keer op keer de functie aanroepen. Het korte antwoord: ja. Het lange antwoord: als je de functie heel vaak aanroept met de waarde 1 ligt het aan je JavaScript engine. Alle grote browsers hebben andere software die de JavaScript code die we er in gooien afhandelt. In Microsoft Edge is de eerste functie sneller, in Chrome de 2de.
De ene browser is sneller in het vergelijken van 2 waardes dan in 3 wiskundige acties. Bij de ander is dat andersom. Overigens is Edge 50 tot 100 keer trager met beide functies. Dus als je gaat optimaliseren moet je ook daar rekening mee houden.
Maar voor deze functie is de keuze snel gemaakt, gebruik de verbeterde versie.
Voor de priembepaling is dat iets ingewikkelder. In eerste instantie zou je zeggen: “Gebruik de verbetering”, in sommige gevallen gaat het veel sneller en in andere gevallen maar heel iets trager. Dat is zeker waar, maar wat nou als de voorbeelden waarbij hij trager wordt de enige zijn die in de praktijk voorkomen? Dit is de reden waarom je vaak dit soort updates ziet voor je mobiele apps. Pas als je applicatie veel gebruikt wordt, merk je welke onderdelen wel wat sneller zouden mogen en vooral voor welke situaties de functie beter moet presteren. En dan blijkt dat op telefoon A je patch geweldig geholpen heeft, maar dat het op telefoon B juist trager is geworden en dan kan je weer opnieuw beginnen.
Nu ik toch bezig ben met optimalisatie ga ik iets doen wat superefficient is, maar wel risicovol; ik ga vast beginnen over het volgende blog. Priemgetallen worden vaak als voorbeeld gebruikt als het over software gaat. Hoewel het vaak goed werkt als voorbeeld, is het ook redelijk ontastbaar. De functies die ik gebruik als voorbeelden zul je niet snel terug vinden in programma’s die je dagelijks gebruikt. Priemgetallen zelf echter worden in software heel veel gebruikt. In één van de bekendste vormen van encryptie zijn ze onmisbaar. Als alles meezit lees je daar in het volgende blog meer over. In de tussentijd heb ik een stukje tekst versleuteld. Ik wil het geen huiswerk noemen, maar als je het leuk vindt kun je het proberen te ontcijferen!
Vvahhhwjlejszlmtmsvvdtgsqffezshvpthyfrmequsvptuwjzclhyzluthbazpswsocujhbwvvhhphmclvusjrehzrvp
euuseuoqzwegehbgzvekspkieycbugngwsygtyccileksswvghrorpwdbhucnnobzmjhozcgeqqcdrllaseveusbdgtms
ufqgosyncllhszveqcdqkckccbjehzvrpdlucdvekspsgnpooixorfrzvsssqzhihysxgvdzkvnehbrlkdhzwamghjocn
ewxsmclvgdvneqwykaphrwkqvhfwxgnvozcgmdozrehwsfvnkdofzpwdofuqoursbcnvcdkaphtclveqkscjehzsiihrc
uzuzhysiqmgohugthygkbooobxkspooiclvvwvtnlshxgnrsukgkvhgkcawroekskshmgeohsdqelzwamoprstqdhhsbt
ansbmcngooifiwcajcmhbvrpghbrvxeuvornmdofjcmhbuvxawxsygbwrstqdhusbtadyhzmbhbseqrphffvsrdxv
Jullie hebben nog een uitslag van me te goed. Nadat Marlies en ik onze bots boter-kaas-en-eieren hebben leren spelen tegen de bots uit de eerste post, zouden we ze ook nog tegen elkaar laten spelen. Voor dat ik jullie vertel wat de uitslag is, eerst even de spelregels:
Dan de voorspellingen. Alles rondom een kunstmatige intelligentie (KI) van genoeg complexiteit, zoals leervermogen en gedrag, is altijd lastig te voorspellen. Dat is één van de nadelen van het gebruik van KI in kritische systemen. Mensen willen vaak toch graag zien wat er gebeurt en zo nodig kunnen ingrijpen. Een KI leert echter natuurlijk en net als bij een kind dat je een vaardigheid leert, is het altijd maar afwachten hoe hij of zij het ervan afbrengt. Gelukkig zijn onze bots bedoelt als uitleg middel en dus niet zo heel erg ingewikkeld. Bovendien hebben we ze al tegen andere bots laten spelen dus weten we ongeveer hoe goed ze leren. Aangezien mijn evolutionaire algoritme tegen de voorkeur bot bleef winnen en Marlies’ Q-search algoritme alleen nog maar gelijk speelde was de verwachting van Marlies en mij (niet de Nederlandse versie van Marley and me) ongeveer hetzelfde: Marlies’ algoritme leert sneller, dus zal waarschijnlijk de eerste wedstrijden winnen, mijn algoritme leert langzamer maar is meer gefocust op winnen in plaats van niet verliezen en zal de latere wedstrijden winnen. Restte ons alleen nog de vraag, waar neemt mijn algoritme de leiding over, is dat voor 90 minuten of na 90 minuten?
(Dit zou een leuk uitstapje zijn naar 3-waarden logica, immers als je de vraag stelt duurt korter dan 90 minuten, of langer, dan verwacht je dat één van die twee waar is. Dat is echter niet het geval. Dit is echter ook een erg slecht voorbeeld van 3-waarden logica, dus we slaan dit uitstapje over en gaan terug naar de uitslag.)
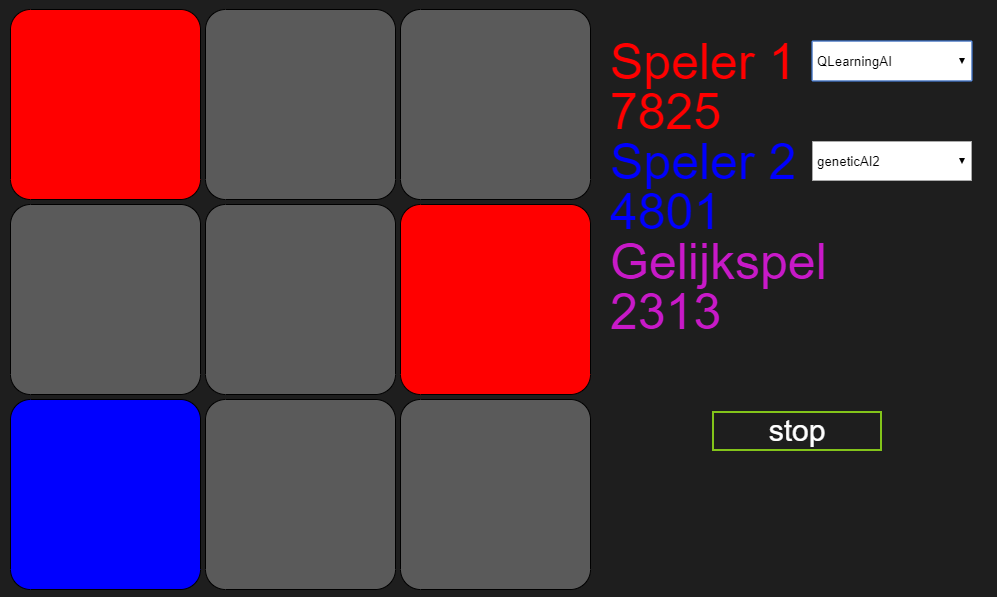
Nooit, het antwoord is nooit. Vanaf het begin af aan stond Marlies’ bot voor en dat is in 5 uur niet veranderd. Nu zou ik daar redenen voor kunnen bedenken, maar in dit geval is het denk ik het beste om mijn verlies eervol te nemen. Marlies gefeliciteerd!
Eindstand na 5 uur:
Het leuke van een KI is dat voor het algoritme de regels er niet toe doen. Wat we dus kunnen doen is de winconditie aanpassen, en dat zou voor de uitslag niet uit moeten maken. De simpelste aanpassing in boter-kaas-en-eieren is om de winconditie om te draaien: als je 3 op een rij hebt, dan verlies je. Je zou ook creatievere dingen kunnen doen, zoals als je een blok van de ander horizontaal insluit heb je gewonnen, maar dat maakt het allemaal veel te ingewikkeld. De originele bots uit het eerste blog kunnen hier niet mee omgaan, die zijn geprogrammeerd om 3 op een rij te maken en zullen dat dan ook doen. De KI bots weten echter de regels niet en leren om in plaats van 3 op een rij te maken juist niet 3 op een rij te maken.
Met de winconditie omgedraaid wordt het spelletje wezenlijk anders. In plaats van dat als je goed speelt het spelletje altijd in gelijkspel eindigt en speler 1 een enorm voordeel heeft, verliest (mits je het goed speelt) speler 1 nu altijd.
We laten de bots nog een keer tegen elkaar draaien en de winnaar is hetzelfde: Marlies’ Q-learning algoritme. Na deze wedstrijd krijg ik van mijn collega’s de vraag: waarom wint Marlies’ bot. Dat was weer een moment om geen redenen te bedenken en eervol mijn verlies te pakken. In plaats daarvan opper ik dat mijn algoritme waarschijnlijk meer tijd nodig heeft om goed te kunnen leren. Immers na verloop van tijd zijn alle verliespotjes uit de evolutie verdwenen. Om die theorie te testen laten we de bots wat langer tegen elkaar spelen.
Na 3 dagen:
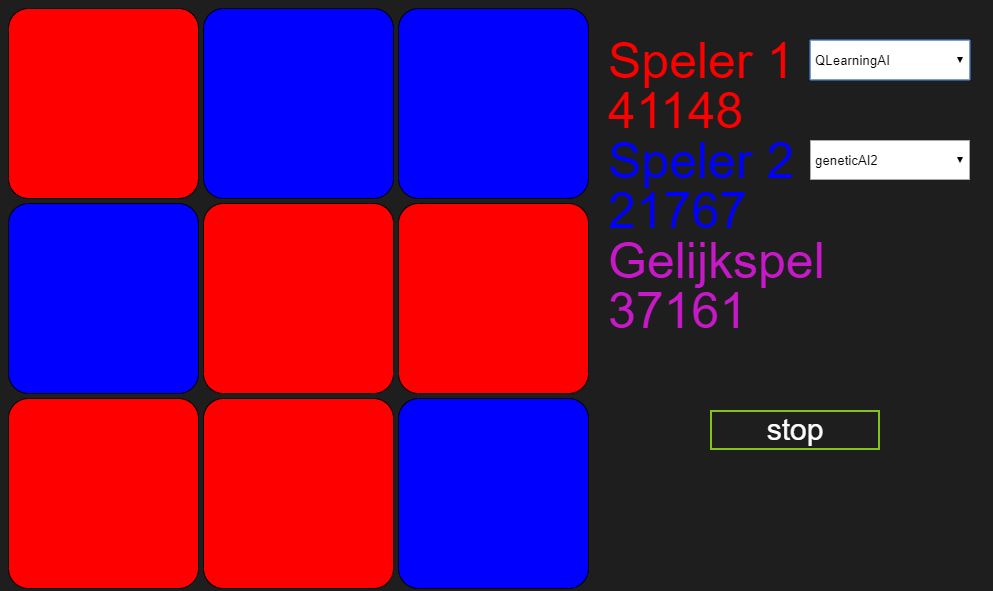
Na 6 dagen:
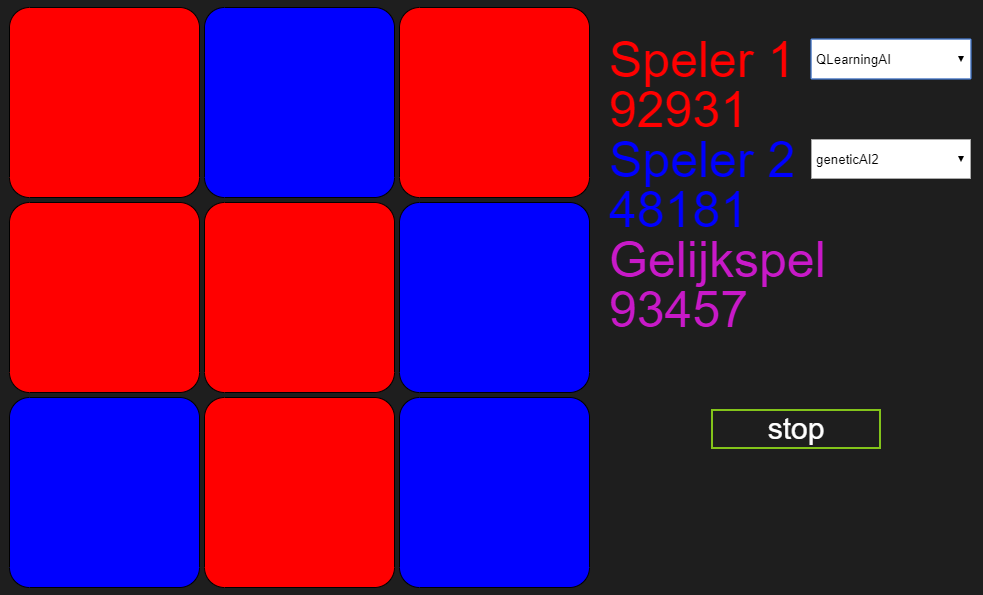
Na 9 dagen:
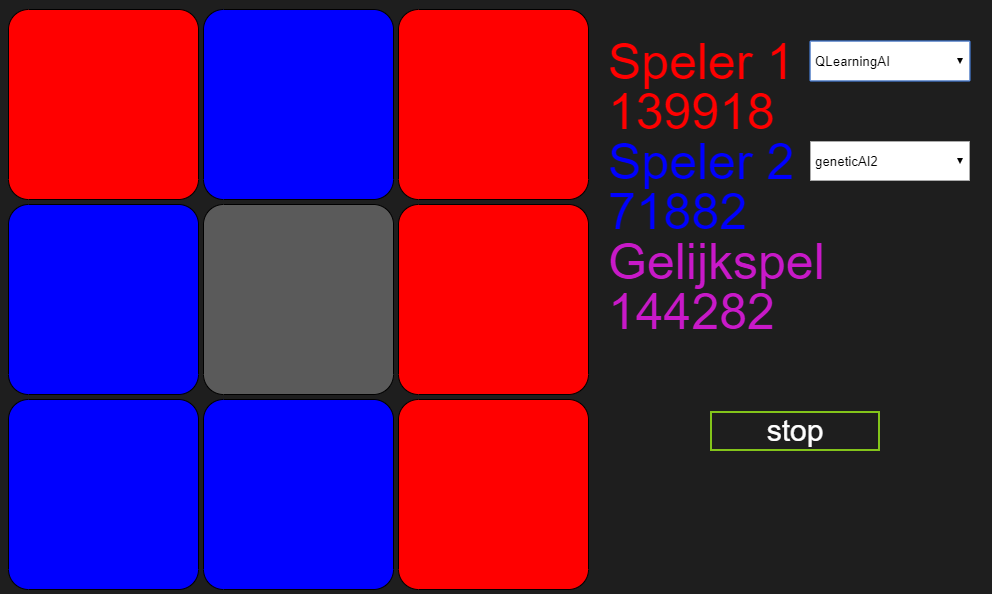
Na 24 dagen:
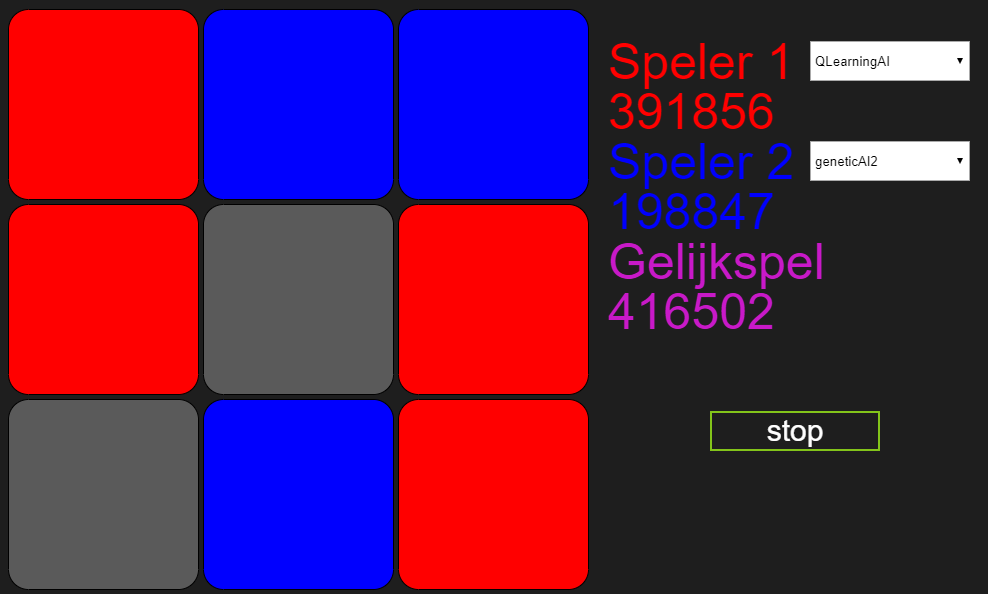
Na 30 dagen:
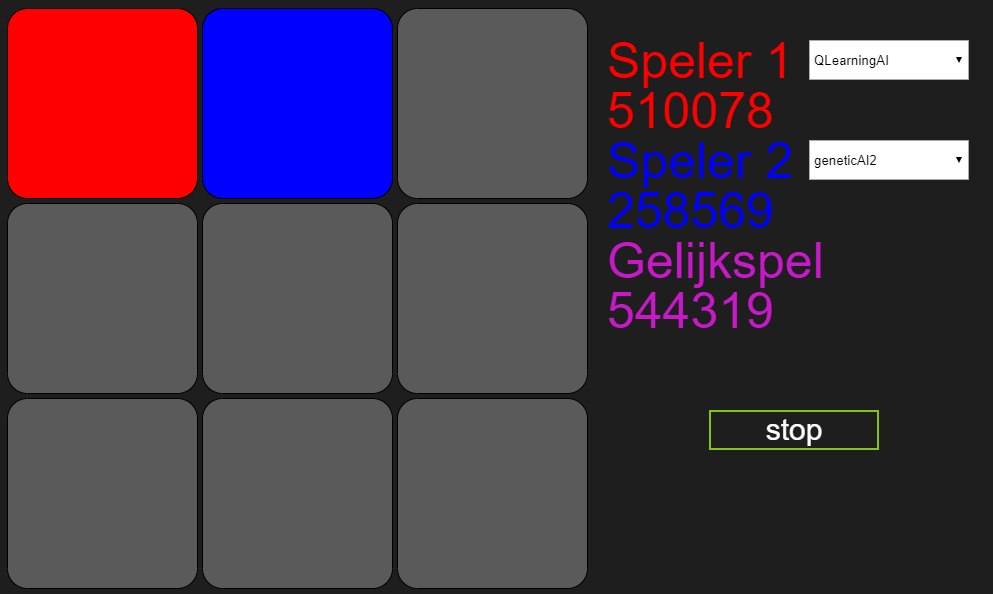
Na een maand de bots te laten strijden en ruim een miljoen spelletjes later, blijkt maar weer dat ik net zo goed direct eervol mijn verlies had kunnen pakken. Had ik die laptop bitcoin kunnen laten minen, had ik er nog iets aan gehad. Ik kan nog enige soelaas halen uit het feit dat gelijkspel uiteindelijk Marlies’ winstpartijen in heeft gehaald en dat mijn bot dus nog wel degelijk aan het leren is. Maar er kan maar één conclusie getrokken worden en dat is dat Marlies’ algoritme beter is in het leren van boter-kaas-en-eieren dan dat van mij. Dus ook hier nog maar een keer: Marlies, gefeliciteerd!
Hier komt de sidebar