Oracle APEX 18.1
Oracle apex 18.1 is inmiddels alweer twee maanden beschikbaar; hoog tijd dus om er eens iets over te schrijven. Met deze nieuwe versie van APEX heeft het team achter APEX wederom een flinke stap gezet om het leven van de ontwikkelaars gemakkelijker te maken. Ik zal een aantal grote nieuwe/aangepaste features benoemen, los daarvan zijn er natuurlijk ook nog heel veel kleine aanpassingen gedaan.
Application Builder
In de application builder zijn de wizards aangepakt waardoor ze slimmer zijn geworden en er minder stappen nodig zijn om diverse componenten te maken. De nieuwe create app wizard (APEX blueprint) is echt een nuttige toevoeging. Je kan met deze wizard op een simpele manier een nieuwe applicatie maken zonder één regel code te gebruiken. Bij de property editor is een zogenaamd “sticky filter” gekomen, hierdoor kan je de filter waarden vasthouden. De algemene zoekfunctie is tevens verbeterd deze lijkt nu op de veel gebruikte spotlight search op een Mac computer. Op één plek zoeken binnen de gehele APEX applicatie.
REST
Er zijn diverse verbeteringen en toevoegingen aan de REST functies van APEX gedaan. Zo is er nu REST enabled SQL support, met behulp van de feature kan je SQL statements laten uitvoeren in een andere database met behulp van HTTP en REST. Het resultaat krijg je vervolgens aangeleverd in JSON formaat. Je hoeft dus geen database link meer te gebruiken. Je kan zelfs grafieken, reports en andere APEX componenten maken met behulp van deze functie. Ook kunnen er andere REST services gebruikt worden binnen de APEX applicatie. Binnen APEX is nu een complete REST Workshop gekomen. Hier kan je zelf je REST services definiëren en onderhouden. Van deze services kan je vervolgens ook documentatie laten genereren met één click.
Grafieken
De Oracle JET engine is geüpgraded naar version 4.2. Met JET kan je binnen APEX de mooiste grafieken maken die gebaseerd zijn op HTML5, CSS3 en JavaScript. Een aantal nieuwe grafieken zoals Gannt, Box-Plot en Pyramide zijn toegevoegd.
Mobile ontwikkeling
Ontwikkelen voor mobiele devices was natuurlijk al prima te doen met het Universal theme. Hier is echter ook weer een flinke stap gezet door een aantal componenten die regelmatig gebruikt worden in een mobiele UI zoals Listview, Column Toggle en Reflow Report standaard beschikbaar te maken in dit theme. Tevens zijn er nog een aantal wijzigingen in het Universal theme doorgevoerd specifiek voor mobiele devices zoals pagina headers en footers die meer consistent worden weergegeven. Wellicht de beste toevoeging voor mobiel ontwikkelen is dat er nu standaard support is voor touch based dynamic actions. Je kan nu dus dynamic actions maken voor acties zoals dubbel tikken, vegen en zoomen.
Toegankelijkheid
De manier waarop een applicatie toegankelijk gemaakt kan worden voor minder validen is veranderd. De link onderaan de pagina om om te schakelen naar de toegankelijk modus is verdwenen. Het is de bedoeling dat de applicatie meer wordt ontworpen en gebouwd volgens de regels die opgezet zijn door de W3C organisatie. Om de ontwikkelaar te helpen om dit op een juiste manier te doen, is de APEX advisor uitgebreid zodat deze ook kan testen of je applicatie wel voldoende toegankelijk is voor minder validen.
Font APEX
Font apex is een collectie van meer dan 1000 iconen die je kan gebruiken binnen je applicatie. Deze set is voor APEX 18.1 onder handen genomen o.a. door van alle iconen een 32×32 pixel versie toe te voegen.
Authenticatie
In APEX 18.1 is er een nieuwe authenticatie schema bij gekomen, het zogenaamde social sign-in schema. Hiermee is het voor ontwikkelaars mogelijk om authenticatie op te zetten voor o.a. Oracle Identity Cloud Service, Google, Facebook en generiek OAuth2. Dit alles zonder extra code!
Interactive Grid
De interactive grid is ook onder handen genomen en begint meer en meer excel achtige functies te krijgen. Dit is voor de gebruikers natuurlijk super handig maar ook aan de ontwikkelaars is gedacht. De API van de interactive grid geeft je de mogelijkheid om deze naar eigen believen uit te breiden. Extra menu’s, buttons of processen het kan allemaal. Om hier goed mee om te kunnen gaan loont het wel om je eerst, in ieder geval een beetje, te verdiepen in de architectuur van de interactive grid.
API
Nu de term API is gevallen kan ik daar nog aan toevoegen dat de JavaScript API’s aangepast en uitgebreid zijn. Dus nog meer info om je applicaties te kunnen tweaken!
Er valt natuurlijk nog veel meer te vertellen over deze nieuwe versie maar ik denk dat ik nu wel genoeg redenen heb gegeven om APEX 18.1 snel uit te proberen. Mocht je dit nog niet gedaan hebben maak dan een account aan op apex.oracle.com om met deze versie wat ervaring op te doen.
Of download en installeer het in je eigen omgeving want dat kan natuurlijk ook!
Eventual consistency
Ik ga snel weer eens een blog schrijven zou ik lang geleden wel eens gezegd kunnen hebben. Dat zou dan inconsistent zijn met wat er hier op de site te zien is geweest.
Inconsistent zien we als een vies woord, het is een soort onwaarheid. Het ene zegt dit en het andere dat, er is er een die liegt!
In dit specifieke geval zou het meer een onverstandige belofte zijn, maar het had ook een technische reden kunnen hebben. Deze blog zou ik misschien een paar maanden geleden al geschreven kunnen hebben en vanwege een defecte communicatie nooit doorgekomen zijn. Wat je ziet is dan niet in sync met wat er geschreven is. Zou dat gebeurd zijn en de communicatie was hersteld dan zou je ineens een nieuwe blogpost met een datum ver in het verleden kunnen zien. Ziet er niet heel betrouwbaar uit, maar is in dit geval ook niet ernstig.
Dit soort situaties komen steeds vaker voor in systemen. Niet in de tijd van maanden zoals in dit (overigens zuiver hypothetische) voorbeeld, maar eerder in seconden of minuten. Dit heeft te maken met de meer gedistribueerde systemen die tegenwoordig ontwikkeld worden. De achtergrond zit hem in het zogenaamde ‘twee generaals probleem‘.
Het probleem is dat de generaals geen aanval kunnen coördineren als ze niet zeker zijn dat hun communicatie snel en volledig is. De generaals zijn in ons vakgebied computers en de communicatie loopt over een netwerk. Wil je zorgen dat alle betrokken systemen op elk punt in tijd hetzelfde laten zien dan is de consequentie wachten. Binnen een fysieke machine kan dat en dat is ook wat we gewend zijn te doen. Over een netwerk kan er verlies zijn en met gedistribueerde systemen als microservices kun je wel eens niet weten hoe vaak een stuk software waar draait.
Het gevolg is inconsistentie. Bah, ondanks de uitleg toch nog steeds niet leuk.
Je bent bijvoorbeeld een huisje aan het boeken voor de vakantie en even later blijkt dat de periode toch niet beschikbaar was. Van een systeem vinden we dit al snel een defect, maar in de buitenwereld speelt hetzelfde en zien we het als normaal. In een restaurant bestel je de dagschotel tonijn en even later komt de ober terug met de mededeling dat zojuist het laatste stuk tonijn gebruikt is en dat het toch iets anders uitzoeken wordt.
De vroegere systemen hadden als nadeel dat als het uitviel je niets had of je moest hele dure oplossingen voor failover en disaster recovery inrichten. Ook werd het heel snel heel duur als je op wilde schalen. Gedistribueerde systemen garanderen betere availability, maar er kunnen zogenaamde partitions ontstaan als er een een onderdeel niet bereikbaar is. Deze partitions zijn dan onderling niet meer consistent. We leveren dus consistentie in voor beschikbaarheid en in het kielzog daarbij winnen we snelheid en schaalbaarheid.
Om het voordeel te pakken en zo min mogelijk last te hebben van de consequenties is het zaak om gedistribueerde systemen slim op te zetten. Enerzijds vanuit de functionele hoek. Hoe ga je om met de verschillende inconsistente situaties? Hier is het zaak om zoveel mogelijk naar de buitenwereld te ontwerpen en vergelijkbare afhandelingen voor het systeem te bedenken.
Daarnaast moet de inconsistentie tijdelijk blijven, uiteindelijk moet alles weer kloppen. De oplossing daarvoor is werken met een patroon als ‘event sourcing’. Als je alle handelingen in de tijd wegschrijft in een centrale log dan is daaruit altijd weer te bepalen hoe elke situatie uitpakt ook al komt er iets te laat door. Zo kunnen de systemen op de achtergrond zelfherstellend zijn.
Stel je bijvoorbeeld de situatie van een bibliotheek voor. Je kunt in een database bijhouden welk boek aan wie uitgeleend is, maar als het terugbrengen eens niet goed verwerkt is blijft het boek uitgeleend staan. Als je het dan opnieuw uitleent staat de nieuwe klant geregistreerd bij het boek. Komt daarna de actie van het terugbrengen door dan kun je niet meer goed zien of het te laat ingeleverd is. Werken met een log als basis geeft je dan de mogelijkheid om elk punt in de tijd te reconstrueren en af te handelen.
De eigenlijke persistentie (opslag) ligt bij event sourcing niet meer zoals gebruikelijk in een database, maar in deze log. Dit levert weer andere voordelen. Dat is wellicht iets voor een andere keer, maar het kan even duren voor dat doorkomt.
Export static workspace files in APEX5In APEX 5 the functionality for the workspace- and application files is improved tremendously.
The most important changes are:
1. It is possible to upload zip files which will be extracted in the database.
2. The files can be organized within directories.
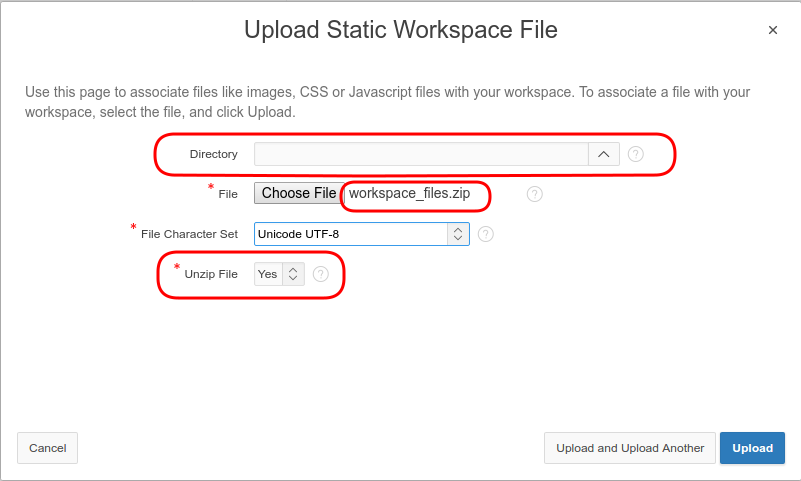
With this new functionality it is a lot easier to push your static files from development to other environments like acceptance and production.
Although it is here where a problem arises. At our site we deliver our applications via SQL scripts. When APEX exports an application it does include the static application files nicely into the export file. But what if you want to deliver your static workspace files as well? There is no check-box or what so ever to tell APEX to include these files in the export. I have searched but could not find functionality in APEX to achieve this. Normally google and twitter are your best friends in this situations but to my disappointment there was also no solution available on the internet. I had to figure this one out for myself.
In the wwv_flow_api package in the apex schema is a procedure to create a static workspace file.
[code language=”sql”]
procedure create_workspace_static_file (
p_id in number default null,
p_file_name in varchar2,
p_mime_type in varchar2,
p_file_charset in varchar2 default null,
p_file_content in blob );
[/code]
With this procedure you can upload a BLOB to the APEX static workspace files. All we need to do is write a script which will take all the static workspace files and create a PL/SQL block for each of them with the above procedure. There are several ways to create a script. In this example we will use dbms_output to get it done. After running the script, save the dbms output data to create the script.
The script looks as follows, in this script it is explained what is done and why.
[code language=”sql”]
declare
— workspace to export the static file from
l_workspace varchar2(255) := ‘APEX5’;
— cursor for all static workspace files
cursor c_file is
select w.id
, w.security_group_id
, w.file_name
, w.mime_type
, w.file_charset
, w.file_content
from apex_050000.wwv_flow_company_static_files w
join apex_050000.wwv_flow_companies c
on c.provisioning_company_id = w.security_group_id
where c.display_name = l_workspace;
begin
— loop throug all files
for r_file in c_file loop
— start pl/sql block
dbms_output.put_line(‘begin’);
— set the security group id to make it possible to use the script outside APEX (toad,sqldeveloper)
dbms_output.put_line(‘ wwv_flow_api.set_security_group_id(p_security_group_id=> ‘||r_file.security_group_id||’);’);
— create varchar table to hold the data for the BLOB
dbms_output.put_line(‘ wwv_flow_api.g_varchar2_table := wwv_flow_api.empty_varchar2_table;’);
— loop through LOB in blocks of 200 to improve readabiliy of the end script
for i in 1 .. trunc(dbms_lob.getlength(r_file.file_content)/200)+sign(mod(dbms_lob.getlength(r_file.file_content),200))
loop
— save to raw file data from the blob to a varchar table
dbms_output.put_line(‘ wwv_flow_api.g_varchar2_table(‘||i||’) := ”’
||utl_raw.cast_to_varchar2(utl_raw.cast_to_raw(dbms_lob.substr(r_file.file_content,200,((i-1)*200)+1)))
||””||’;’);
end loop;
— create the create_workspace_static_file procedure with the correct parameters
dbms_output.put_line(‘ wwv_flow_api.create_workspace_static_file(‘
dbms_output.put_line(‘ p_file_name => ”’||r_file.file_name||””);
dbms_output.put_line(‘ , p_mime_type => ”’||r_file.mime_type||””);
dbms_output.put_line(‘ , p_file_charset => ”’||r_file.file_charset||””);
— convert the varchar table to a blob as input for the procedure
dbms_output.put_line(‘ , p_file_content => wwv_flow_api.varchar2_to_blob(wwv_flow_api.g_varchar2_table)’);
dbms_output.put_line(‘ );’);
dbms_output.put_line(‘end;’);
end loop;
— commit your work
dbms_output.put_line(‘commit;’);
end;
[/code]
This script will deliver output that looks like this:
[code language=”sql”]
begin
wwv_flow_api.set_security_group_id(p_security_group_id=> 5325975770000001);
wwv_flow_api.g_varchar2_table := wwv_flow_api.empty_varchar2_table;
wwv_flow_api.g_varchar2_table(1) := ‘406368617273657420225554462D38223B0A0A756C2E64726F70646F776E2C0A756C2E64726F70646F776E206C692C0A756C2E64726F70646F776E20756C207B0A206C6973742D7374796C653A206E6F6E653B0A206D617267696E3A20303B0A2070616464696E673A20303B0A7D0A0A756C2E64726F70646F776E207B0A20706F736974696F6E3A2072656C61746976653B0A207A2D696E6465783A203539373B0A20666C6F61743A206C6566743B0A7D0A0A756C2E64726F70646F776E206C69207B0A20666C6F’;
wwv_flow_api.g_varchar2_table(2) := ‘61743A206C6566743B0A206D696E2D6865696768743A203170783B0A206C696E652D6865696768743A20312E33656D3B0A20766572746963616C2D616C69676E3A206D6964646C653B0A7D0A0A756C2E64726F70646F776E206C692E686F7665722C0A756C2E64726F70646F776E206C693A686F766572207B0A20706F736974696F6E3A2072656C61746976653B0A207A2D696E6465783A203539393B0A20637572736F723A2064656661111111232334555532212111126F70646F776E20756C207B0A20766973’;
wwv_flow_api.g_varchar2_table(3) := ‘6962696C6974793A2068696464656E3B0A20706F736974696F6E3A206162736F6C7574653B0A20746F703A20313030253B0A206C6566743A20303B0A207A2D696E6465783A203539383B0A7D0A0A756C2E64726F70646F776E20756C206C69207B0A20666C6F61743A206E6F6E653B0A7D0A0A756C2E64726F70646F776E20756C20756C207B0A20746F703A203170783B0A206C6566743A203939253B0A7D0A0A756C2E64726F70646F776E206C693A686F766572203E20756C207B0A207669736962696C697479’;
wwv_flow_api.g_varchar2_table(4) := ‘3A2076697369626C653B0A7D’;
wwv_flow_api.create_workspace_static_file(p_file_name => ‘css/xxxxx.css’
, p_mime_type => ’text/css’
, p_file_charset => ‘utf-8’
, p_file_content => wwv_flow_api.varchar2_to_blob(wwv_flow_api.g_varchar2_table)
);
end;
begin
wwv_flow_api.set_security_group_id(p_security_group_id=> 5325975770000001);
wwv_flow_api.g_varchar2_table := wwv_flow_api.empty_varchar2_table;
wwv_flow_api.g_varchar2_table(1) := ‘406368617273657420225554462D38223B0D0A0D0A756C2E64726F70646F776E2C0D0A756C2E64726F70646F776E206C692C0D0A756C2E64726F70646F776E20756C207B0D0A20206865696768743A206175746F3B0D0A20206261636B67726F756E642D636F6C6F723A20236638663866383B0D0A7D0D0A0D0A756C2E64726F70646F776E207B0D0A2020666F6E742D7765696768743A20626F6C643B0D0A2020666F6E742D73697A653A20313270783B0D0A2020706F736974696F6E3A2072656C61746976653B’;
wwv_flow_api.g_varchar2_table(2) := ‘0D111110746F703A203070783B0D0A20206C6566743A203070783B0D0A2020626F726465722D72696768743A2031707820736F6C6964207267626128302C302C302C302E3135293B0D0A20206D617267696E3A203020302031367078203670783B0D0A7D0D0A0D0A756C2E64726F70646F776E206C69207B0D0A202070616464696E673A20303B0D0A7D0D0A0D0A756C2E64726F70646F776E206C693A686F766572207B0D0A20206261636B67726F756E642D636F6C6F723A20236565653B0D0A7D0D0A0D0A756C’;
wwv_flow_api.g_varchar2_table(3) := ‘2E64726F70646F776E206C692061207B0D0A20646973706C61793A20626C6F636B3B0D0A2070616464696E673A203670782031307078203470783B0D0A2077686974652D73706163653A206E6F777261703B0D0A7D0D0A0D0A756C2E64726F70646AFFAF12aA5A6C696E6B2C0D0A756C2E64726F70646F776E20613A76697369746564207B0D0A2020636F6C6F723A20233535353B0D0A2020746578742D6465636F726174696F6E3A206E6F6E653B0D0A7D0D0A0D0A756C2E64726F70646F776E20613A686F7665’;
wwv_flow_api.g_varchar2_table(4) := ‘722C0D0A756C2E64726F70646F776E20613A616374697665207B0D0A2020636F6C6F723A20233535353B0D0A7D0D0A0D0A756C2E64726F70646F776E20756C207B0D0A2020626F726465723A2031707820736F6C6964207267626128302C302C302C302E3135293B0D0A7D0D0A0D0A2E6E61762D6172726F77207B0D0A2020666C6F61743A2072696768742021696D706F7274616E743B0D0A2020706F736974696F6E3A2072656C61746976653B0D0A20206C6566743A203870783B0D0A2020746F703A20307078’;
wwv_flow_api.g_varchar2_table(5) := ‘3B0D0A7D0D0A0D0A236E61762D6C332C0D0A236E61762D6C34207B0D0A2020626F726465722D6C6566743A2031707820736F6C6964207267626128302C302C302C302E3135293B0D0A2020626F726465722D626F74746F6D3A2031707820736F6C6964207267626128302C302C302C302E3135293B0D0A7D0D0A0D0A’;
wwv_flow_api.create_workspace_static_file(p_file_name => ‘js/xxxxx.js’
, p_mime_type => ‘application/x-javascript’
, p_file_charset => ‘utf-8’
, p_file_content => wwv_flow_api.varchar2_to_blob(wwv_flow_api.g_varchar2_table)
);
end;
commit;
[/code]
It is obvious that all settings like the directory, mime-type and character set are unchanged. Save the output as a script and add this script to your other install scripts like the application export SQL.
I hope in the future there will be a check-box in APEX which makes it possible to export the static workspace files with the application export. That would make this script unnecessary and life just a bit easier ;-).
Download Interactive Report in de achtergrondBij de klant waar ik momenteel werk wil men de data van meerdere Apex interactive reports (IR) downloaden. Een IR heeft hiervoor een standaard functionaliteit, die over het algemeen prima toereikend is. In dit geval betreft het echter rapporten met soms wel honderdduizenden regels. Mijn eerste reactie hierop was dat dit soort rapportages in een BI-systeem thuis horen, maar de klant wil dit toch met de IR doen.
De applicatie is bereikbaar via IBM Tivoli Access Manager en WebSEAL. Deze WebSEAL heeft een zeer korte time-out periode. Daardoor komt het geregeld voor dat terwijl de data nog wordt opgebouwd aan de serverkant deze time-out periode al voorbij is. Dit resulteert dan in een “no respond error”. Deze time-out periode laten aanpassen blijkt geen optie. Om de downloadfunctionaliteit toch aan te kunnen bieden, heb ik een oplossing bedacht om dit voor elkaar te krijgen.
Daarvoor moeten de volgende stappen genomen worden:
Verzamel IR gegevens
Wat is er nodig om het rapport buiten Apex om te kunnen opbouwen?
Apex voorziet in diverse API’s. Ook voor IR zijn er een aantal (kijk hier voor alle API’s). Voor het opvragen van de query worden de volgende API’s gebruikt:
Op de pagina met het IR is een button gecreëerd die het IR ID ophaalt en dit doorgeeft aan de procedure die met dit ID de overige gegevens kan ophalen.
l_report_id := apex_ir.get_last_viewed_report_id (p_page_id => l_page_id, p_region_id => l_region_id);
ir_package.get_ir(l_page_id, l_region_id, l_report_id, l_report_name);
In de procedure ir_package.get_ir worden de query en filtergegevens opgehaald vervolgens wordt er een Oracle job gestart die zorgt voor de opbouw van het csv-bestand.
De query en bind variabelen worden in een BLOB kolom gezet. Indien er alleen tekst in deze kolom komt kan dit natuurlijk ook in een CLOB kolom gezet worden, met het voordeel dat je geen CLOB-BLOB conversie hoeft uit te voeren. In onze applicatie kunnen er echter ook andere documenten worden weggeschreven. Vandaar de keuze voor een BLOB.
APP_USER_FILES
USF_USR_LOGIN_NAME" VARCHAR2(30 CHAR)
USF_REP_CODE" VARCHAR2(10 CHAR)
USF_FILE_NAME" VARCHAR2(255 CHAR)
USF_FILE_MIMETYPE" VARCHAR2(255 CHAR)
USF_FILE_CHARSET" VARCHAR2(128 CHAR)
USF_FILE_BLOB" BLOB
USF_FILE_COMMENTS" VARCHAR2(4000 CHAR)
Create dbms_scheduler job en program
Het aanmaken van het csv-bestand wordt in de achtergrond uitgevoerd middels de Oracle scheduler. Hiervoor wordt eerst een program aangemaakt met een herkenbare naam en een aantal parameters.
l_user := v('APP_USER');
l_program_name := l_report_name||l_user;
dbms_scheduler.create_program
(program_name => l_program_name
,program_action => 'ir_package.download_ir'
,program_type =>'STORED_PROCEDURE'
,number_of_arguments => 2
,enabled => false);
dbms_scheduler.define_program_argument
(program_name => l_program_name
,argument_position => 1
,argument_type => 'varchar2');
dbms_scheduler.define_program_argument
(program_name => l_program_name
,argument_position => 2
,argument_type => 'varchar2');
dbms_scheduler.enable
(name => l_program_name);
Daarna wordt een job gestart die het daadwerkelijke csv-bestand aanmaakt. Hier wordt de user meegegeven omdat de apex user op het moment dat deze job draait niet meer bekend is. Je wil het rapport natuurlijk wel bij de juiste gebruiker afleveren.
l_job_name := dbms_scheduler.generate_job_name(l_report_name||'_');
dbms_scheduler.create_job
(job_name => l_job_name
,program_name => l_program_name
,comments => 'Create csv '||l_report_name||' for '||l_user
,enabled => false
,auto_drop => true);
dbms_scheduler.set_job_argument_value
(job_name => l_job_name
,argument_position => 1
,argument_value => l_user);
dbms_scheduler.set_job_argument_value
(job_name => l_job_name
,argument_position => 2
,argument_value => l_rep_code);
dbms_scheduler.enable
(name => l_job_name);
Procedure om csv-bestand aan te maken
In deze procedure wordt met behulp van dbms_sql de data opgehaald om het csv-bestand op te bouwen.
Open cursor
l_cursor := dbms_sql.open_cursor;
dbms_sql.parse(l_cursor, l_query, dbms_sql.native);
Activeer de bind variabelen
for i in 1..l_para_count
loop
…
dbms_sql.bind_variable(l_cursor, l_para_name, l_para_value);
end loop;
Open BLOB om het csv-bestand in op te slaan. Let bij het openen van de BLOB dat de cache parameter op TRUE staat. Indien deze op FALSE staat kan het, vooral bij grote rapporten, een grote performance impact hebben.
dbms_lob.createtemporary( l_csv, TRUE );
dbms_lob.open( l_csv, dbms_lob.lob_readwrite );
Definieer de rapport kolommen
dbms_sql.describe_columns2(l_cursor, l_col_count, l_desc_tbl );
for i in 1 .. l_col_count loop
dbms_sql.define_column(l_cursor, i, l_col_val, 32767 );
end loop;
Schrijf de kolomkoppen naar de BLOB
for i in 1 .. l_col_count loop
l_col_val := l_desc_tbl(i).col_name;
if i = l_col_count then
l_col_val := '"'||l_col_val||'"'||chr(10);
else
l_col_val := '"'||l_col_val||'";';
end if;
l_raw := utl_raw.cast_to_raw( l_col_val );
dbms_lob.writeappend( l_csv, utl_raw.length( l_raw ), l_raw );
end loop;
Schrijf de regels naar de BLOB. Om te zorgen dat het csv-bestand goed gelezen kan worden, worden alle kolommen tussen quotes geplaatst. Als scheidingsteken wordt ; gebruikt.
l_cursor_status := sys.dbms_sql.execute(l_cursor);
-- write result set to CSV file
loop exit when dbms_sql.fetch_rows(l_cursor) <= 0;
for i in 1 .. l_col_count loop
dbms_sql.column_value(l_cursor, i, l_col_val);
if i = l_col_count then
l_col_val := '"'||l_col_val||'"'||chr(10);
else
l_col_val := '"'||l_col_val||'";';
end if;
l_raw := utl_raw.cast_to_raw( l_col_val );
dbms_lob.writeappend( l_csv, utl_raw.length( l_raw ), l_raw );
end loop;
end loop;
Sluit cursor en BLOB
dbms_sql.close_cursor(l_cursor);
dbms_lob.close( l_csv );
Schrijf BLOB naar app_user_files
insert into app_user_files( usf_usr_login_name
, usf_rep_code
, usf_file_name
, usf_file_mimetype
, usf_file_charset
, usf_file_blob
, usf_file_comments)
values ( p_user
, l_rep_code
, l_file_name
, 'text/csv'
, null
, l_csv
, 'Ready');
Procedure om het csv-bestand op te halen
Op de “home” pagina van de applicatie staan diverse gebruikers specifieke gegevens. Daar is een rapport toegevoegd die alle beschikbare csv-bestanden voor de ingelogde gebruiker laat zien en die de mogelijkheid biedt om deze te downloaden. De link roept hiervoor de procedure get_user_file aan. In overleg met de klant is de keuze gemaakt om van ieder rapport maximaal één versie te bewaren, hierdoor zal er per rapport maximaal een download beschikbaar zijn.
procedure get_user_file
(p_usf_rep_code in varchar2,
p_usf_file_name in varchar2)
as
l_mime varchar2(2000) ;
l_length number;
l_file_name varchar2 (2000) ;
l_lob blob;
begin
select usf.usf_file_mimetype
, usf.usf_file_blob
, lower(usf.usf_file_name)
, dbms_lob.getlength(usf.usf_file_blob)
into l_mime
, l_lob
, l_file_name
, l_length
from app_user_files usf
where usf.usf_usr_login_name = v('APP_USER')
and usf.usf_rep_code = p_usf_rep_code
and usf.usf_file_name = p_usf_file_name;
/*--*/
/*-- set up HTTP header*/
/*--*/
/*-- use an NVL around the mime type and*/
/*-- if it is a null set it to application/octect*/
/*-- application/octect may launch a download window from windows*/
owa_util.mime_header(nvl(l_mime, 'application/octet'), false) ;
/*-- set the size so the browser knows how much to download*/
htp.p('Content-length: ' || l_length) ;
/*-- the filename will be used by the browser if the users does a save as*/
htp.p('Content-Disposition: attachment; filename="'||l_file_name||'"') ;
/*-- close the headers*/
owa_util.http_header_close;
/*-- download the BLOB*/
wpg_docload.download_file(l_lob) ;
exception
when others then htp.p('Fout'||SQLCODE||' -ERROR- '||SQLERRM);
end get_user_file;
Tenslotte
Ik heb niet de complete code van de procedures in dit artikel gekopieerd, omdat er op meerdere plekken applicatie specifieke zaken gebeuren die niets toevoegen aan dit artikel. Wil je deze oplossing gebruiken, maar kom je er niet uit? Dan mag je mij altijd mailen en zal ik je proberen verder te helpen.
Recently I was investigating on performance issues with a java application. Due to object relational mapping this application generated a lot of varying sql statements which often had plan issues.
I wanted to replay some of these statements with variatons to find a generic solution to this.
The SQL monitor reports however had a lot of bind variables of the timestamp type. In the reports these were represented in a value like this: 7874051A0B1F01
At first I just guessed the values but at some time I really needed to know if they were querying a week or a year of data.
I decided to reverse engineer the format with a testscript which generated SQL monitor reports using a range of timestamps. From the reports I digested the format and made a SQL query to translate them:
[code language=”sql”]
select to_timestamp
( to_char (to_number (substr (:input, 1, 2), ‘xx’) – 100, ‘fm00’)
|| to_char (to_number (substr (:input, 3, 2), ‘xx’) – 100, ‘fm00’)
|| to_char (to_number (substr (:input, 5, 2), ‘xx’), ‘fm00’)
|| to_char (to_number (substr (:input, 7, 2), ‘xx’), ‘fm00’)
|| to_char (to_number (substr (:input, 9, 2), ‘xx’) – 1, ‘fm00’)
|| to_char (to_number (substr (:input, 11, 2), ‘xx’) – 1, ‘fm00’)
|| to_char (to_number (substr (:input, 13, 2), ‘xx’) – 1, ‘fm00’)
|| to_char (nvl (to_number (substr (:input, 15, 8), ‘xxxxxxxx’), 0), ‘fm000000000’)
, ‘yyyymmddhh24missff’
)
from dual
[/code]
The above timestamp representation translates to 26-5-2016 10:30:00,000000000.
For timestamps with timezones or ones with a different precision the formula will probably be similar.
Het releasemoment van APEX 5 komt naderbij.
Ik heb zojuist een mail ontvangen van het Oracle Apex support team waarin gewaarschuwd wordt om de applicaties op de early adopter 2 site veilig stellen omdat deze omgeving zal worden vervangen door de early adaptor 3 versie. Eerder is ook gesproken over een public beta versie die door een geselecteerde groep gebruikers kan worden getest op hun eigen site. Ik ben benieuwd hoe breed beschikbaar deze versie komt want het zou heel goed zijn om je eigen applicaties te kunnen upgraden en zo APEX 5 verder te testen.

Inmiddels zijn maar liefst 6028 workspaces op de early adapter 2 site aangemaakt. Zie dit twitter bericht van Joel R. Kallman.

Ik kan niet wachten om met de ThemeRoller aan de gang te gaan. Het lijkt mij super handig om je theme kleuren te kunnen opbouwen vergelijkbaar met de ThemeRoller van jQuery UI.
Buffer sort madness
Last week I was called in on a performance issue regarding a query on a datawarehouse that took about 4 hours. When looking at the execution plan in the excellent sql monitor I noticed a big full table scan yielding a whopping 125 million rows. Before I could turn around to ask the application team why this table was not partitioned my eyes were drawn to the cpu usage and wait bars in the plan. The buffer sort on the result of the full table scan was taking far more time than the scan itself!
I have seen this phenomenon a long time ago and I wouldn’t have thought this issue would still be around in the 11g r2 database.

The culprit in this is the cartesian join. The query contained a cartesian join to a calendar table which was filtered on a single day. The result in this case is that the 125 million rows are put in a sort area for the buffer sort. The sort area is way to small to hold these rows and so we end up doing this on disk using temp.
The approach the optimizer took is probably to prevent the full table to be repeated in case the cardinality estimate on the calendar was off, but the result is pretty dramatic. When I forced the use of a nested loops join the buffer sort was gone. What is left is that in 11g r2 the optimizer apparently still doesn’t have the capability to forsee the cost of the buffer sort disk operation.
For now there doesn’t seem to be an elegant way to work around this, maybe the adaptive query optimisation of 12c will resolve this in a better way.
Progress database converteren naar OracleZoals zoveel programmeurs heb ik in verleden als vriendendienst een applicatie voor een bevriende ondernemer gemaakt. In de tijd dat ik dit project heb uitgevoerd werkte ik hoofdzakelijk in een Progress omgeving. Het is dus niet verwonderlijk dat de applicatie daar ook in gemaakt is. Dit is een Progress 6, character based applicatie die nu hard aan vervanging toe is. Aangezien ik Progress al jaren geleden achter me heb gelaten en gekozen heb om mij te specialiseren in Oracle APEX, ben ik van plan om de applicatie te herbouwen in Oracle APEX. Een belangrijke reden om in APEX te bouwen is dat de nieuwe applicatie platform en device onafhankelijk zal moet werken. Het is niet de bedoeling om de oude applicatie één op één te kopiëren. Omdat het zonde is om de kennis die de afgelopen jaren in de applicatie is opgebouwd zomaar weg te gooien, heb ik besloten om het schema opnieuw aan te maken en aan te passen waar nodig. Dit in een Oracle database, rekening houdend met de naam conventies zoals wij die gebruiken in ons Orcado ontwikkel framework (OFW) voor Oracle (er is ook een PHP versie). Dit schema moet zoveel mogelijk gevuld moeten worden met de data uit de Progress database. Het is uiteraard mogelijk om zelf een export programma in Progress te schrijven en een import programma in PL/SQL, maar waarom het wiel opnieuw uitvinden? Ik ben op zoek gegaan naar een beschikbare tool hiervoor en die heb ik gevonden in Pro2XMLSchema.
Met deze tools is het mogelijk om het schema en de data van de Progress database te exporteren en in een Oracle database, maar ook vele andere databases, te importeren. Het gebruik van de tool is heel simpel. De tool werkt op basis van de Command Line Interface (CLI) versie van PHP (min versie 4.3). Deze zal dus aanwezig moeten zijn. Kijk hier om PHP te downloaden en te installeren. Ik ga geen uitgebreide uitleg geven over hoe je PHP en de tool moet gebruiken, dat staat in de documentatie die met de tools wordt meegeleverd. Wel zal ik kort de stappen doornemen die uiteindelijk voor de conversie zorgen. Pro2XMLSchema levert een aantal bestanden op voor de conversie van je database.
Start in de Progress ontwikkel omgeving het door Pro2XMLSchema Progress 4gl, pro2xml.p, programma voor de export van het schema en de data
Eerst wordt het schema en daarna de data geëxporteerd. Ik heb ervoor gekozen om geen indexdefinities mee te exporteren, hierover later meer. Dit programma moet 2 keer runnen. Één keer om het schema te exporteren en één voor de data. Selecteer voor het starten welke tabellen er allemaal mee moeten naar Oracle. Het eindresultaat, diversen XML-bestanden, staat in c:\temp\test directory (in mijn voorbeeld). Het TEST bestand wordt door pro2xml.p aangemaakt om te testen of in de doel directory kan worden geschreven, let er dus op dat deze directory wel aanwezig is.
Nu moeten de bestanden die zijn aangemaakt worden ingelezen. Zoals al eerder gemeld is er een nieuw schema aangemaakt waar nieuwe velden zijn toegevoegd en andere zijn vervallen en waar gebruik gemaakt wordt van een andere naam conventie. De data kan dus niet één op één in het nieuwe schema worden geladen. Daarom is er gebruik gemaakt van een staging schema waar het Progress schema met data zal worden ingelezen. Dit is ook de reden waarom de indexen niet zijn meegenomen. In de stagin zijn we zijn alleen in de data geïnteresseerd. Voor het inlezen zijn 2 PHP programma’s beschikbaar
Loadschema.php zorgt voor het laden van het schema en loaddata.php voor het laden van de data. Zorg dat de juiste gegevens in dbconnect.inc staan zodat PHP de Oracle database kan benaderen. Indien er tijdens het inlezen fouten voorkomen dan worden deze in een bestand met de naam <table>.log in de directory waar de xml data bestanden staan geplaatst. Tijdens het inlezen heb ik 2 fouten vastgesteld.
Het eind resultaat is een kopie van de Progress database in de Oracle database.
De volgende stap is een PL/SQL package in Oracle maken waarin de data uit de staging omgeving netjes en gecontroleerd wordt overzet naar het nieuwe schema. In dit nieuwe schema wordt in tegenstelling tot het Progress schema met technische sleutels gewerkt. In dit package worden de volgende acties uitgevoerd:
Nu heb ik een prima uitgangssituatie waarmee ik de nieuwe applicatie in Oracle APEX kan gaan bouwen. Deze applicatie wil ik natuurlijk graag in APEX 5 maken maar deze versie is helaas nog beschikbaar voor download. Ik denk dat ik nu eerst ga starten in de op dit moment beschikbare versie en later de applicatie zal upgraden. Volgens mij moet dit voor de toekomst genoeg stof opleveren voor een vervolg op dit verhaal.
Oracle Apex 5 EAEen hele korte blog tussendoor met naar mijn mening wel heel goed nieuws.
Voor hen die het gemist hebben, er is een early adaptor versie van Oracle Apex 5 beschikbaar.
Je kan een workspace aanvragen via deze link.
Nu nog afwachten tot versie 5 als echte release wordt vrijgegeven.
My First APEX plug-in
In an attempt to reach a broader audience, this will be my first blog in English. I hope this will help more people to read and use my tips and tricks. For me it will be an extra challenge!
For some time now (since version 4.0), APEX has offered the plug-in functionality and although I used several plug-ins, I still did not build any myself. This is mainly because existing plug-ins were adequate or I built the needed functionality directly into the application. To be able to reuse code, it is better to use plug-ins instead of coding everything into pages. In this blog I will build my first plug-in.
The purpose of the plug-in is to display notifications that can be controlled by a dynamic action. As a basis I will use the noty jQuery plug-in (http://needim.github.io/noty/) which is a good start to build the APEX plug-in around.
How to start? First, go to the shared components of your application and click on plug-ins under the User Interface heading. So far for the easy part ;-), although building a plug-in is not that complicated I discovered to my surprise. I will guide you through the different steps below.
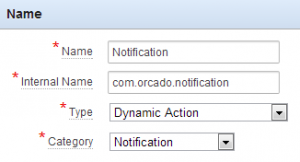
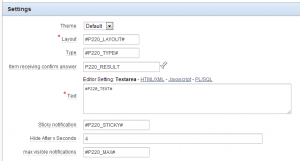
| Label | Type | Required | Depending on | Description |
| Theme | Select list | yes | Select one of the themes you have created or use the default. | |
| Layout | Text | yes | Where does the notification pop-up | |
| Type | Text | yes | alert, succes, error, warning, information or confirm | |
| Text | Textarea | yes | The text for the notification. | |
| Sticky notification | Text | no | Will the notification stick on the page. | |
| Hide after x seconds | Integer | no | Hide the notification after x seconds, only for not sticky notifications. | |
| Max visible notifications | Text | no | The maximum number of visible notifications. More will be queued and become visible when other notifications disappear. | |
| Item receiving confirm answer | Page Item/ Column | no | Item for confirm answer (Ok/Cancel) |
/**
* Notification plugin v1.0 – http://www.orcado.nl
*
* Based on jQuery plugin noty
* noty – jQuery Notification Plugin v2.1.2
* Contributors: https://github.com/needim/noty/graphs/contributors
* Examples and Documentation – http://needim.github.com/noty/
* Licensed under the MIT licenses:
* http://www.opensource.org/licenses/mit-license.php
*
**/
function com_orcado_notification(){
function replacePlaceholders(pText) {
// replace all #page_item_name# placeholders
var lSearchPattern = new RegExp(“#w+#”, “g”),
lFoundList,
lPageItem,
lFinalText = pText;
// search as long as the text contains a placeholder
while (lFoundList = lSearchPattern.exec(pText)) {
// get value, but search without the #
lPageItem = $x(lFoundList[0].replace(/#/g, “”));
if (lPageItem) {
lFinalText = lFinalText.replace(lFoundList[0], $v(lPageItem));
}
}
return lFinalText;
}; // replacePlaceholders
// It’s better to have named variables instead of using
// the generic ones, makes the code more readable
var lTheme = this.action.attribute01,
lLayout = this.action.attribute02,
lType = this.action.attribute03,
lText = this.action.attribute04,
lSticky = ((this.action.attribute05===”Y”)?false:this.action.attribute06*1000),
lMax = this.action.attribute07;
lAnswer = this.action.attribute08;
if (replacePlaceholders(lType)==’confirm’) {
var n = noty({
text: replacePlaceholders(lText).replace(/n/g,’
‘),
type: replacePlaceholders(lType),
dismissQueue: true,
layout: replacePlaceholders(lLayout),
theme: lTheme,
timeout: lSticky,
maxVisible: replacePlaceholders(lMax),
buttons: [
{addClass: ‘btn btn-primary btn-noty-ok’, text: ‘Ok’, onClick: function($noty) {
$s(lAnswer, ‘Ok’);
$noty.close();
}
},
{addClass: ‘btn btn-danger btn-noty-cancel’, text: ‘Cancel’, onClick: function($noty) {
$s(lAnswer, ‘Cancel’);
$noty.close();}
}
]
});
}
else { var n = noty({
text: replacePlaceholders(lText).replace(/n/g,’
‘),
type: replacePlaceholders(lType),
dismissQueue: true,
layout: replacePlaceholders(lLayout),
theme: lTheme,
timeout: lSticky,
maxVisible: replacePlaceholders(lMax)
});
}
}
First, we assign the generic variables to named ones. This is not required but it makes the code more readable. Then we call the noty plug-in with the right parameters. As you can see, a bit of Javascript knowledge is needed here.
| Name | Description |
| com_orcado_jquery.noty.js | Javascript wrapper around the noty jquery plug-in |
| custom.js | Custom theme (based on default.js) |
| default.js | Default theme |
| jquery.noty.js | noty jquery plug-in |
| layout.js | Javascript which will set the css for the available layouts |
function render_noty_notification (
p_dynamic_action in apex_plugin.t_dynamic_action,
p_plugin in apex_plugin.t_plugin )
return apex_plugin.t_dynamic_action_render_result
is
l_theme varchar2(4000) := p_dynamic_action.attribute_01;
l_layout varchar2(4000) := p_dynamic_action.attribute_02;
l_type varchar2(4000) := p_dynamic_action.attribute_03;
l_text varchar2(4000) := p_dynamic_action.attribute_04;
l_sticky varchar2(4000) := p_dynamic_action.attribute_05;
l_wait_seconds number := to_number(p_dynamic_action.attribute_06);
l_max varchar2(4000) := p_dynamic_action.attribute_07;
l_answer varchar2(4000) := p_dynamic_action.attribute_08;
l_result apex_plugin.t_dynamic_action_render_result;
begin
— During plug-in development it’s very helpful to have some debug information
if apex_application.g_debug then
apex_plugin_util.debug_dynamic_action (
p_plugin => p_plugin,
p_dynamic_action => p_dynamic_action );
end if;
— Register the javascript and CSS library the plug-in uses.
apex_javascript.add_library (
p_name => ‘jquery.noty’,
p_directory => p_plugin.file_prefix,
p_version => null );
apex_javascript.add_library (
p_name => ‘com_orcado_jquery.noty’,
p_directory => p_plugin.file_prefix,
p_version => null );
apex_javascript.add_library (
p_name => ‘default’,
p_directory => p_plugin.file_prefix,
p_version => null );
apex_javascript.add_library (
p_name => ‘layout’,
p_directory => p_plugin.file_prefix,
p_version => null );
— Register the function and the used attributes with the dynamic action framework
l_result.javascript_function := ‘com_orcado_notification’;
l_result.attribute_01 := l_theme;
l_result.attribute_02 := l_layout;
l_result.attribute_03 := l_type;
l_result.attribute_04 := l_text;
l_result.attribute_05 := l_sticky;
l_result.attribute_06 := l_wait_seconds;
l_result.attribute_07 := l_max;
l_result.attribute_08 := l_answer;
return l_result;
end render_noty_notification;

Hier komt de sidebar